无论在哪个平台,并发编程都是一个让人头疼的问题。庆幸的是,相对于服务端,客户端的并发编程简单了许多。这篇文章主要讲述一些基于 iOS 平台的一些并发编程相关东西,我写博客习惯于先介绍原理,后介绍用法,毕竟对于 API 的使用,官网有更好的文档。
一些原理性的东西 为了便于理解,这里先解释一些相关概念。如果你对这些概念已经很熟悉,可以直接跳过。
1.进程 从操作系统定义上来说,进程就是系统进行资源分配和调度的基本单位,系统创建一个线程后,会为其分配对应的资源。在 iOS 系统中,进程可以理解为就是一个 App。iOS 并没有提供可以创建进程的 API,即使你调用 fork() 函数,也不能创建新的进程。所以,本文所说的并发编程,都是针对线程来说的 。
2.线程 线程是程序执行流的最小单元。一般情况下,一个进程会有多个线程,或者至少有一个线程。一个线程有创建、就绪、运行、阻塞和死亡五种状态。线程可以共享进程的资源,所有的问题也是因为共享资源引起的。
3.并发 操作系统引入线程的概念,是为了使过个 CPU 更好的协调运行,充分发挥他们的并行处理能力。例如在 iOS 系统中,你可以在主线程中进行 UI 操作,然后另启一些线程来处理与 UI 操作无关的事情,两件事情并行处理,速度比较快。这就是并发的大致概念。
4.时间片 按照 wiki 上面解释:是分时操作系统分配给每个正在运行的进程微观上的一段CPU时间(在抢占内核中是:从进程开始运行直到被抢占的时间)。线程可以被认为是 ”微进程“,因此这个概念也可以用到线程方面。
一般操作系统使用时间片轮转算法进行调度,即每次调度时,总是选择就绪队列的队首进程,让其在CPU上运行一个系统预先设置好的时间片。一个时间片内没有完成运行的进程,返回到绪队列末尾重新排队,等待下一次调度。不同的操作系统,时间片的范围不一致,一般都是毫秒(ms)级别。
4.死锁 死锁是由于多个线程(进程)在执行过程中,因为争夺资源而造成的互相等待现象,你可以理解为卡主了。产生死锁的必要条件有四个:
互斥条件 : 指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。
请求和保持条件 : 指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放。
不可剥夺条件 : 指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放。
环路等待条件 : 指在发生死锁时,必然存在一个进程——资源的环形链,即进程集合{P0,P1,P2,···,Pn}中的P0正在等待一个P1占用的资源;P1正在等待P2占用的资源,……,Pn正在等待已被P0占用的资源。
为了便于理解,这里举一个例子:一座桥,同一时间只允许一辆车经过(互斥 )。两辆车 A,B 从桥的两端开上桥,走到桥的中间。此时 A 车不肯退(不可剥夺 ),又想占用 B 车所占据的道路;B 车此时也不肯退,又想占用 A 车所占据的道路(请求和保持 )。此时,A 等待 B 占用的资源,B 等待 A 占用的资源(环路等待 ),两车僵持下去,就形成了死锁现象 。
5.线程安全 当多个线程同时访问一块共享资源(例如数据库),因为时序性问题,会导致数据错乱,这就是线程不安全 。例如数据库中某个整形字段的 value 为 0,此时两个线程同时对其进行写入操作,线程 A 拿到原值为 0,加一后变为 1;线程 B 并不是在 A 加完后拿的,而是和 A 同时拿的,加完后也是 1,加了两次,理想值应该为 2,但是数据库中最终值却是 1。实际开发场景可能要比这个复杂的多。
所谓的线程安全,可以理解为在多个线程操作(例如读写操作)这部分数据时,不会出现问题。
Lock 因为线程共享进程资源,在并发情况下,就会出现线程安全问题。为了解决此问题,就出现了锁这个概念。在多线程环境下,当你访问一些共享数据时,拿到访问权限,给数据加锁,在这期间其他线程不可访问,直到你操作完之后进行解锁,其他线程才可以对其进行操作。
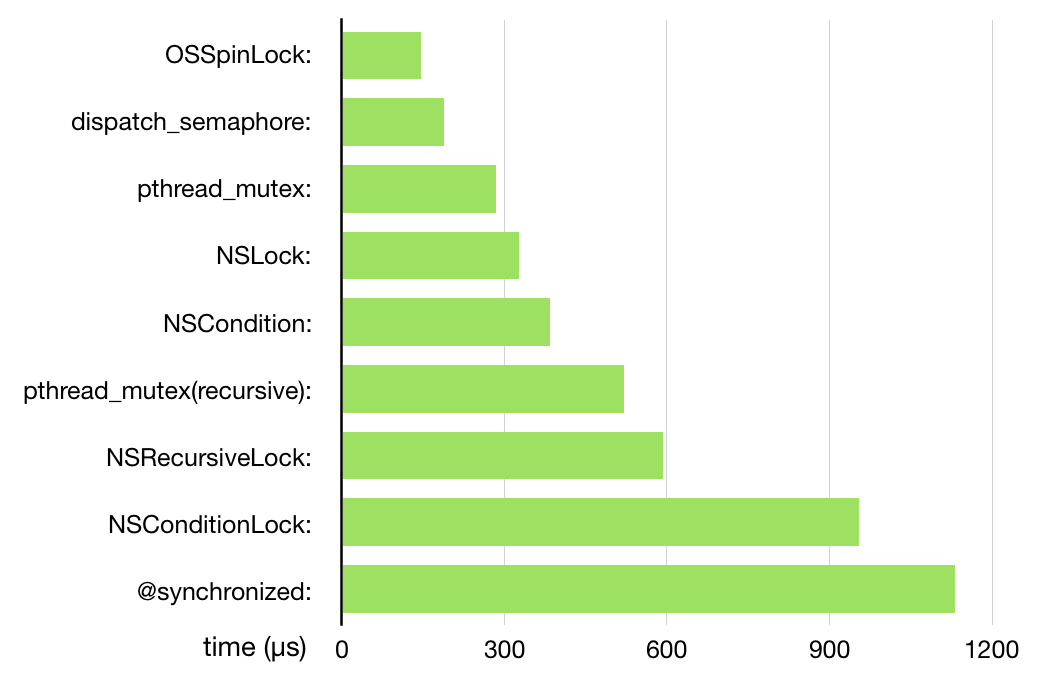
iOS 提供了多种锁,ibireme 大神的 这篇文章 对这些锁进行了性能分析,我这里直接把图 cp 过来了:
下面针对这些锁,逐一分析。
1.OSSpinLock ibireme 大神的文章也说了,虽然这个锁性能最高,但是已经不安全了,建议不再使用,这里简单说一下。
OSSpinLock 是一种自旋锁,主要提供了加锁(OSSpinLockLock)、尝试枷锁(OSSpinLockTry)和解锁(OSSpinLockUnlock)三个方法。对一块资源进行加锁时,如果尝试加锁失败,不会进入睡眠状态,而是一直进行询问(自旋),占用 CPU资源,不适用于较长时间的任务。在自旋期间,因为占用 CPU 导致低优先级线程拿不到 CUP 资源,无法完成任务并释放锁,从而形成了优先级反转 。
so,虽然性能很高,但是不要用了。而且 Apple 也已经将这个类比较为 deprecate 了。
自旋锁 & 互斥锁
优先级反转 :当一个高优先级任务访问共享资源时,该资源已经被一个低优先级任务抢占,阻塞了高优先级任务;同时,该低优先级任务被一个次高优先级的任务所抢先,从而无法及时地释放该临界资源。最终使得任务优先级被倒置,发生阻塞。(引用自 wiki
关于自旋锁的原理,bestswifter 的文章 深入理解 iOS 开发中的锁 这篇文章讲得很好,我这里大部分锁的知识引用于此,建议读一下原文。
自旋锁是加不上就一直尝试,也就是一个循环,直到尝试加上锁,伪代码如下:
1 2 3 4 5 6 7 bool lock = false ; do { while (test_and_set(&lock); Critical section lock = false ; Reminder section }
使用 :
1 2 3 4 OSSpinLock spinLock = OS_SPINLOCK_INIT; OSSpinLockLock(&spinLock); OSSpinLockUnlock(&spinLock);
2.dispatch_semaphore dispatch_semaphore 并不属于锁,而是信号量。两者的区别如下:
锁是用于线程互斥操作,一个线程锁住了某个资源,其他线程都无法访问,直到整个线程解锁;信号量用于线程同步,一个线程完成了某个动作通过信号量告诉别的线程,别的线程再进行操作。
锁的作用域是线程之间;信号量的作用域是线程和进程之间。
信号量有时候可以充当锁的作用,初次之前还有其他作用。
如果转化为数值,锁可以认为只有 0 和 1;信号量可以大于零和小于零,有多个值。
dispatch_semaphore 使用分为三步:create、wait 和 signal。如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 dispatch_semaphore_t semaphore = dispatch_semaphore_create(1 ); dispatch_async (dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0 ), ^{ dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER); NSLog (@"task A" ); sleep(10 ); dispatch_semaphore_signal(semaphore); }); dispatch_async (dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0 ), ^{ dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER); NSLog (@"task B" ); dispatch_semaphore_signal(semaphore); });
执行结果:
1 2 2018 -05 -03 21 :40 :09.068586 +0800 ConcurrencyTest[44084 :1384262 ] task A2018 -05 -03 21 :40 :19.072951 +0800 ConcurrencyTest[44084 :1384265 ] task B
thread A,B 是两个异步线程,一般情况下,各自执行自己的事件,互不干涉。但是根据 console 输出,B 是在 A 执行完了 10s 执行之后才执行的,显然受到阻塞。使用 dispatch_semaphore 大致执行过程这样:创建 semaphore 时,信号量值为 1;执行到线程 A 的 dispatch_semaphore_wait 时,信号量值减 1,变为 0;然后执行任务 A,执行完毕后 sleep 方法阻塞当前线程 10s;与此同时,线程 B 执行到了 dispatch_semaphore_wait,由于信号量此时为 0,且线程 A 中设置的为 DISPATCH_TIME_FOREVER,因此需要等到线程 A sleep 10s 之后,执行 dispatch_semaphore_signal 将信号量置为 1,线程 B 的任务才开始执行。
根据上面的描述,dispatch_semaphore 的原理大致也就了解了。GCD 源码 对这些方法定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 long dispatch_semaphore_wait(dispatch_semaphore_t dsema, dispatch_time_t timeout) { long value = dispatch_atomic_dec2o(dsema, dsema_value); dispatch_atomic_acquire_barrier(); if (fastpath(value >= 0 )) { return 0 ; } return _dispatch_semaphore_wait_slow(dsema, timeout); } static long _dispatch_semaphore_wait_slow(dispatch_semaphore_t dsema, dispatch_time_t timeout) { long orig; again: while ((orig = dsema->dsema_sent_ksignals)) { if (dispatch_atomic_cmpxchg2o(dsema, dsema_sent_ksignals, orig, orig - 1 )) { return 0 ; } } struct timespec _timeout ; int ret; switch (timeout) { default : do { uint64_t nsec = _dispatch_timeout(timeout); _timeout.tv_sec = (typeof(_timeout.tv_sec))(nsec / NSEC_PER_SEC); _timeout.tv_nsec = (typeof(_timeout.tv_nsec))(nsec % NSEC_PER_SEC); ret = slowpath(sem_timedwait(&dsema->dsema_sem, &_timeout)); } while (ret == -1 && errno == EINTR); if (ret == -1 && errno != ETIMEDOUT) { DISPATCH_SEMAPHORE_VERIFY_RET(ret); break ; } case DISPATCH_TIME_NOW: while ((orig = dsema->dsema_value) < 0 ) { if (dispatch_atomic_cmpxchg2o(dsema, dsema_value, orig, orig + 1 )) { errno = ETIMEDOUT; return -1 ; } } case DISPATCH_TIME_FOREVER: do { ret = sem_wait(&dsema->dsema_sem); } while (ret != 0 ); DISPATCH_SEMAPHORE_VERIFY_RET(ret); break ; } goto again; }
以上时对 wait 方法的定义,如果你不想看代码,可以直接听我说:
调用 dispatch_semaphore_wait 方法时,如果信号量大于 0,直接返回;否则进入后续步骤。
_dispatch_semaphore_wait_slow 方法根据传入 timeout 参数不同,使用 switch-case 处理。如果传入的是 DISPATCH_TIME_NOW 参数,将信号量加 1 并立即返回。
如果传入的是一个超时时间,调用系统的 semaphore_timedwait 方法进行等待,直至超时。
如果传入的是 DISPATCH_TIME_FOREVER 参数,调用系统的 semaphore_wait 进行等待,直到收到 singal 信号。
至于 dispatch_semaphore_signal 就比较简单了,源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 long dispatch_semaphore_signal(dispatch_semaphore_t dsema) { dispatch_atomic_release_barrier(); long value = dispatch_atomic_inc2o(dsema, dsema_value); if (fastpath(value > 0 )) { return 0 ; } if (slowpath(value == LONG_MIN)) { DISPATCH_CLIENT_CRASH("Unbalanced call to dispatch_semaphore_signal()" ); } return _dispatch_semaphore_signal_slow(dsema); }
现将信号量加 1,大于 0 直接返回。
小于 0 返回 _dispatch_semaphore_signal_slow,这个方法的作用是调用内核的 semaphore_signal 函数唤醒信号量,然后返回 1。
3.pthread_mutex Pthreads 是 POSIX Threads 的缩写。pthread_mutex 属于互斥锁,即尝试加锁失败后悔阻塞线程并睡眠,会进行上下文切换。锁的类型主要有三种:PTHREAD_MUTEX_NORMAL、PTHREAD_MUTEX_ERRORCHECK、PTHREAD_MUTEX_RECURSIVE。
PTHREAD_MUTEX_NORMAL,普通锁,当一个线程加锁以后,其余请求锁的线程将形成一个等待队列,并在解锁后按优先级获得锁。这种锁策略保证了资源分配的公平性。
PTHREAD_MUTEX_ERRORCHECK,检错锁,如果同一个线程请求同一个锁,则返回 EDEADLK。否则和 PTHREAD_MUTEX_NORMAL 相同。
PTHREAD_MUTEX_RECURSIVE,递归锁,允许一个线程进行递归申请锁。
使用如下:
1 2 3 4 5 6 7 8 9 pthread_mutex_t mutex; pthread_mutexattr_t attr; pthread_mutexattr_init(&attr); pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_NORMAL); pthread_mutex_init(&mutex, &attr); pthread_mutex_lock(&mutex); pthread_mutex_unlock(&mutex);
4.NSLock NSLock 属于互斥锁,是 Objective-C 封装的一个对象。虽然我们不知道 Objective-C 是如何实现的,但是我们可以在 swift 源码 中找到他的实现 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ... internal var mutex = _PthreadMutexPointer.allocate(capacity: 1 )... open func lock () pthread_mutex_lock(mutex) } open func unlock () pthread_mutex_unlock(mutex) #if os(macOS) || os(iOS) pthread_mutex_lock(timeoutMutex) pthread_cond_broadcast(timeoutCond) pthread_mutex_unlock(timeoutMutex) #endif }
可以看出他只是将 pthread_mutex 封装了一下。只因为比 pthread_mutex 慢一些,难道是因为方法层级之间的调用,多了几次压栈操作???
常规使用:
1 2 3 4 NSLock *mutexLock = [NSLock new];[mutexLock lock]; [muteLock unlock];
4.NSCondition & NSConditionLock NSCondition 可以同时起到 lock 和条件变量的作用。同样你可以在 swift 源码 中找到他的实现 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 open class NSCondition : NSObject , NSLocking internal var mutex = _PthreadMutexPointer.allocate(capacity: 1 ) internal var cond = _PthreadCondPointer.allocate(capacity: 1 ) public override init () { pthread_mutex_init(mutex, nil ) pthread_cond_init(cond, nil ) } deinit { pthread_mutex_destroy(mutex) pthread_cond_destroy(cond) mutex.deinitialize(count : 1 ) cond.deinitialize(count : 1 ) mutex.deallocate() cond.deallocate() } open func lock () pthread_mutex_lock(mutex) } open func unlock () pthread_mutex_unlock(mutex) } open func wait () pthread_cond_wait(cond, mutex) } open func wait (until limit: Date) Bool { guard var timeout = timeSpecFrom(date: limit) else { return false } return pthread_cond_timedwait(cond, mutex, &timeout) == 0 } open func signal () pthread_cond_signal(cond) } open func broadcast () pthread_cond_broadcast(cond) } open var name: String ? }
可以看出,它还是遵循 NSLocking 协议,lock 方法同样还是使用的 pthread_mutex,wait 和 signal 使用的是 pthread_cond_wait 和 pthread_cond_signal。
使用 NSCondition 是,先对要操作的临界区加锁,然后因为条件不满足,使用 wait 方法阻塞线程;待条件满足之后,使用 signal 方法进行通知。下面是一个 生产者-消费者的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 NSCondition *condition = [NSCondition new];NSMutableArray *products = [NSMutableArray array];dispatch_async (dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0 ), ^{ [condition lock]; while (products.count == 0 ) { [condition wait]; } [products removeObjectAtIndex:0 ]; [condition unlock]; }); dispatch_async (dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0 ), ^{ [condition lock]; [products addObject:[NSObject new]]; [condition signal]; [condition unlock]; });
NSConditionLock 是通过使用 NSCondition 来实现的,遵循 NSLocking 协议,然后这是 swift 源码 (源码比较占篇幅,我这里简化一下):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 open class NSConditionLock : NSObject , NSLocking internal var _cond = NSCondition () ... open func lock (whenCondition condition: Int) let _ = lock(whenCondition: condition, before: Date .distantFuture) } open func `try `() Bool { return lock(before: Date .distantPast) } open func tryLock (whenCondition condition: Int) Bool { return lock(whenCondition: condition, before: Date .distantPast) } open func unlock (withCondition condition: Int) _cond.lock() _thread = nil _value = condition _cond.broadcast() _cond.unlock() } open func lock (before limit: Date) Bool { _cond.lock() while _thread != nil { if !_cond.wait(until: limit) { _cond.unlock() return false } } _thread = pthread_self() _cond.unlock() return true } open func lock (whenCondition condition: Int, before limit: Date) Bool { _cond.lock() while _thread != nil || _value != condition { if !_cond.wait(until: limit) { _cond.unlock() return false } } _thread = pthread_self() _cond.unlock() return true } ... }
可以看出它使用了一个 NSCondition 全局变量来实现 lock 和 unlock 方法,都是一些简单的代码逻辑,就不详细说了。
使用 NSConditionLock 注意:
初始化 NSConditionLock 会设置一个 condition,只有满足这个 condition 才能加锁。
-[unlockWithCondition:] 并不是满足条件时解锁,而是解锁后,修改 condition 值 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 typedef NS_ENUM (NSInteger , CTLockCondition ) { CTLockConditionNone = 0 , CTLockConditionPlay , CTLockConditionShow }; - (void )testConditionLock { NSConditionLock *conditionLock = [[NSConditionLock alloc] initWithCondition:CTLockConditionPlay ]; dispatch_async (dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0 ), ^{ [conditionLock lockWhenCondition:CTLockConditionNone ]; NSLog (@"thread one" ); sleep(2 ); [conditionLock unlock]; }); dispatch_async (dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0 ), ^{ sleep(1 ); if ([conditionLock tryLockWhenCondition:CTLockConditionPlay ]) { NSLog (@"thread two" ); [conditionLock unlockWithCondition:CTLockConditionShow ]; NSLog (@"thread two unlocked" ); } else { NSLog (@"thread two try lock failed" ); } }); dispatch_async (dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0 ), ^{ sleep(2 ); if ([conditionLock tryLockWhenCondition:CTLockConditionPlay ]) { NSLog (@"thread three" ); [conditionLock unlock]; NSLog (@"thread three locked success" ); } else { NSLog (@"thread three try lock failed" ); } }); } dispatch_async (dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0 ), ^{ sleep(4 ); if ([conditionLock tryLockWhenCondition:CTLockConditionShow ]) { NSLog (@"thread four" ); [conditionLock unlock]; NSLog (@"thread four unlocked success" ); } else { NSLog (@"thread four try lock failed" ); } }); }
然后看输出结果 :
1 2 3 4 5 2018 -05 -05 16 :34 :33.801855 +0800 ConcurrencyTest[97128 :3100768 ] thread two2018 -05 -05 16 :34 :33.802312 +0800 ConcurrencyTest[97128 :3100768 ] thread two unlocked2018 -05 -05 16 :34 :34.804384 +0800 ConcurrencyTest[97128 :3100776 ] thread three try lock failed2018 -05 -05 16 :34 :35.806634 +0800 ConcurrencyTest[97128 :3100778 ] thread four2018 -05 -05 16 :34 :35.806883 +0800 ConcurrencyTest[97128 :3100778 ] thread four unlocked success
可以看出,thread one 因为条件和初始化不符,加锁失败,未输出 log; thread two 条件相符,解锁成功,并修改加锁条件;thread three 使用原来的加锁条件,显然无法加锁,尝试加锁失败; thread four 使用修改后的条件,加锁成功。
5. NSRecursiveLock NSRecursiveLock 属于递归锁。然后这是 swift 源码 ,只贴一下关键部分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 open class NSRecursiveLock: NSObject, NSLocking { ... public override init() { super.init() #if CYGWIN var attrib : pthread_mutexattr_t? = nil #else var attrib = pthread_mutexattr_t() #endif withUnsafeMutablePointer(to: &attrib) { attrs in pthread_mutexattr_settype(attrs, Int32(PTHREAD_MUTEX_RECURSIVE)) pthread_mutex_init(mutex, attrs) } } ... }
它是使用 PTHREAD_MUTEX_RECURSIVE 类型的 pthread_mutex_t 初始化的。递归所可以在一个线程中重复调用,然后底层会记录加锁和解锁次数,当二者次数相同时,才能正确解锁,释放这块临界区。
使用例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 - (void )testRecursiveLock { NSRecursiveLock *recursiveLock = [NSRecursiveLock new]; int (^__block fibBlock)(int ) = ^(int num) { [recursiveLock lock]; if (num < 0 ) { [recursiveLock unlock]; return 0 ; } if (num == 1 || num == 2 ) { [recursiveLock unlock]; return num; } int newValue = fibBlock(num - 1 ) + fibBlock(num - 2 ); [recursiveLock unlock]; return newValue; }; int value = fibBlock(10 ); NSLog (@"value is %d" , value); }
6. @synchronized @synchronized 是牺牲性能来换取语法上的简洁。如果你想深入了解,建议你去读 这篇文章 。这里说一下他的大概原理:
@synchronized 的加锁过程,大概是这个样子:
1 2 3 4 5 6 @try { objc_sync_enter(obj); } @finally { objc_sync_exit(obj); }
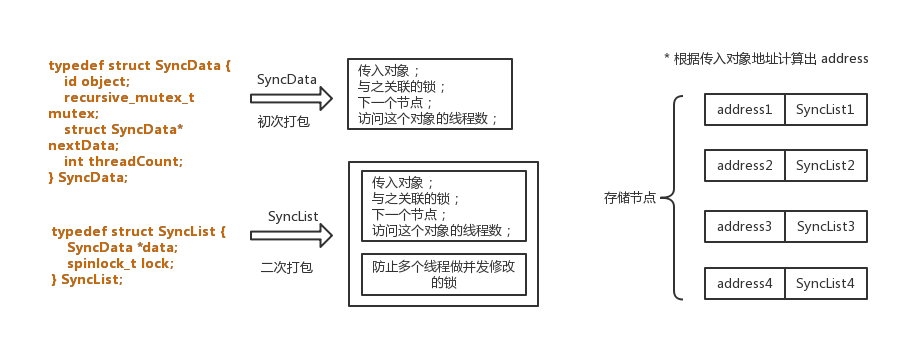
@synchronized 的存储结构,是使用哈希表来实现的。当你传入一个对象后,会为这个对象分配一个锁。锁和对象打包成一个对象,然后和一个锁在进行二次打包成一个对象,可以理解为 value;通过一个算法,根据对象的地址得到一个值,作为 key。然后以 key-value 的形式写入哈希表。结构大概是这个样子:
存储的时候,是以哈希表结构存储,不是我上面画的顺序存储,上面只是一个节点而已。
@synchronized 的使用就很简单了 :
1 2 3 4 5 NSMutableArray *elementArray = [NSMutableArray array]; @synchronized (elementArray) { [elementArray addObject:[NSObject new]]; }
Pthreads 前面也说了,pthreads 是 POSIX Threads 的缩写。这个东西一般我们用不到,这里简单介绍一下。Pthreads 是POSIX的线程标准,定义了创建和操纵线程的一套API。实现POSIX 线程标准的库常被称作Pthreads,一般用于Unix-like POSIX 系统,如Linux、 Solaris。
NSThread NSThread 是对内核 mach kernel 中的 mach thread 的封装,一个 NSThread 对象就是一个线程。使用频率比较低,除了 API 的使用,没什么可讲的。如果你已经熟悉这些 API,可以跳过这一节了。
1.初始化线程执行一个 task 使用初始化方法初始化一个 NSTherad 对象,调用 -[cancel]、-[start、-[main] 方法对线程进行操作,一般线程执行完即销毁,或者因为某种异常退出。
1 2 3 4 5 6 7 8 9 - (instancetype )initWithBlock:(void (^)(void ))block; + (void )detachNewThreadWithBlock:(void (^)(void ))block; + (void )detachNewThreadSelector:(SEL)selector toTarget:(id )target withObject:(nullable id )argument;
2.在主线程执行一个 task 1 2 3 4 - (void )performSelectorOnMainThread:(SEL)aSelector withObject:(nullable id )arg waitUntilDone:(BOOL )wait modes:(nullable NSArray <NSString *> *)array; - (void )performSelectorOnMainThread:(SEL)aSelector withObject:(nullable id )arg waitUntilDone:(BOOL )wait;
3.在其他线程执行一个 task 1 2 3 4 - (void )performSelector:(SEL)aSelector onThread:(NSThread *)thr withObject:(nullable id )arg waitUntilDone:(BOOL )wait modes:(nullable NSArray <NSString *> *)array; - (void )performSelector:(SEL)aSelector onThread:(NSThread *)thr withObject:(nullable id )arg waitUntilDone:(BOOL )wait
4.在后台线程执行一个 task 1 - (void )performSelectorInBackground:(SEL)aSelector withObject:(nullable id )arg;
5.获取当前线程 1 @property (class , readonly , strong ) NSThread *currentThread;
使用线程相关方法时,记得设置好 name,方便后面调试。同时也设置好优先级等其他参数。
performSelector: 系列方法已经不太安全,慎用。
Grand Central Dispatch (GCD) GCD 是基于 C 实现的一套 API,而且是开源的,如果有兴趣,可以在 这里 down 一份源码研究一下。GCD 是由系统帮我们处理多线程调度,很是方便,也是使用频率最高的。这一章节主要讲解一下 GCD 的原理和使用。
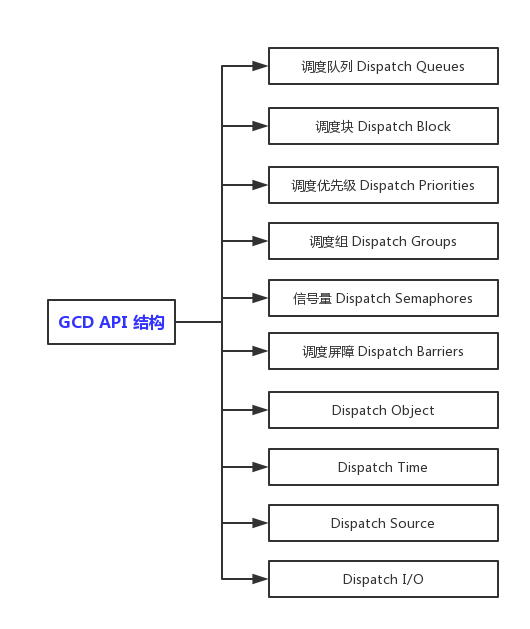
在讲解之前,我们先有个概览,看一下 GCD 为我们提供了那些东西:
系统所提供的 API,完全可以满足我们日常开发需求了。下面就根据这些模块分别讲解一下。
1. Dispatch Queue GCD 为我们提供了两类队列,串行队列 和 并行队列 。两者的区别是:
串行队列中,按照 FIFO 的顺序执行任务,前面一个任务执行完,后面一个才开始执行。
并行队列中,也是按照 FIFO 的顺序执行任务,只要前一个被拿去执行,继而后面一个就开始执行,后面的任务无需等到前面的任务执行完再开始执行。
除此之外,还要解释一个容易混淆的概念,并发 和并行 :
并发:是指单独部分可以同时执行,但是需要系统决定怎样发生。
并行:两个任务互不干扰,同时执行。单核设备,系统需要通过切换上下文来实现并发;多核设备,系统可以通过并行来执行并发任务。
最后,还有一个概念,同步 和异步 :
同步 : 同步执行的任务会阻塞当前线程。
异步 : 异步执行的任务不会阻塞当前线程。是否开启新的线程,由系统管理。如果当前有空闲的线程,使用当前线程执行这个异步任务;如果没有空闲的线程,而且线程数量没有达到系统最大,则开启新的线程;如果线程数量已经达到系统最大,则需要等待其他线程中任务执行完毕。
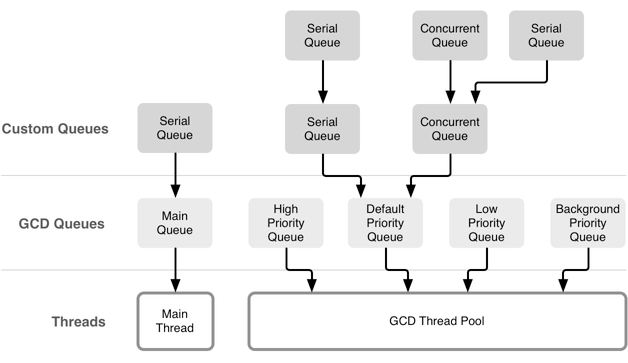
队列 我们使用时,一般使用这几个队列:
你可以使用 dispatch_queue_set_specific、dispatch_queue_get_specific 和 dispatch_get_specific 方法,为 queue 设置关联的 key 或者根据 key 找到关联对象等操作。
可以说,系统为我们提供了 5 中不同的队列,运行在主线程中的 main queue;3 个不同优先级的 global queue; 一个优先级更低的 background queue。除此之外,开发者可以自定义一些串行和并行队列,这些自定义队列中被调度的所有 block 最终都会被放到系统全局队列和线程池中,后面会讲这部分原理。盗用一张经典图:
同步 VS 异步 我们大多数情况下,都是使用 dispatch_asyn() 做异步操作,因为程序本来就是顺序执行,很少用到同步操作。有时候我们会把 dispatch_syn() 当做锁来用,以达到保护的作用。
系统维护的是一个队列,根据 FIFO 的规则,将 dispatch 到队列中的任务一一执行。有时候我们想把一些任务延后执行以下,例如 App 启动时,我想让主线程中一个耗时的工作放在后,可以尝试用一下 dispatch_asyn(),相当于把任务重新追加到了队尾。
1 2 3 dispatch_async (dispatch_get_main_queue(), ^{ });
通常情况下,我们使用 dispatch_asyn() 是不会造成死锁的。死锁一般出现在使用 dispatch_syn() 的时候。例如:
1 2 3 dispatch_sync (dispatch_get_main_queue(), ^{ NSLog (@"dead lock" ); });
想上面这样写,启动就会报错误。以下情况也如此:
1 2 3 4 5 6 7 dispatch_queue_t queue = dispatch_queue_create("com.bool.dispatch" , DISPATCH_QUEUE_SERIAL); dispatch_async (queue, ^{ NSLog (@"dispatch asyn" ); dispatch_sync (queue, ^{ NSLog (@"dispatch asyn -> dispatch syn" ); }); });
在上面的代码中,dispatch_asyn() 整个 block(称作 blcok_asyn) 当做一个任务追加到串行队列队尾,然后开始执行。在 block_asyn 内部中,又进行了 dispatch_syn(),想想要执行 block_syn。因为是串行队列,需要前一个执行完(block_asyn),再执行后面一个(block_syn);但是要执行完 block_asyn,需要执行内部的 block_syn。互相等待,形成死锁。
现实开发中,还有更复杂的死锁场景。不过现在编译器很友好,我们能在编译执行时就检测到了。
基本原理 针对下面这几行代码,我们分析一下它的底层过程:
1 2 3 4 5 6 7 - (void )viewDidLoad { [super viewDidLoad]; dispatch_queue_t queue = dispatch_queue_create("com.bool.dispatch" , DISPATCH_QUEUE_SERIAL); dispatch_async (queue, ^{ NSLog (@"dispatch asyn test" ); }); }
创建队列
源码很长,但实际只有一个方法,逻辑比较清晰,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 dispatch_queue_t dispatch_queue_create(const char *label, dispatch_queue_attr_t attr) { return _dispatch_queue_create_with_target(label, attr, DISPATCH_TARGET_QUEUE_DEFAULT, true ); } DISPATCH_NOINLINE static dispatch_queue_t _dispatch_queue_create_with_target(const char *label, dispatch_queue_attr_t dqa, dispatch_queue_t tq, bool legacy) { if (!slowpath(dqa)) { dqa = _dispatch_get_default_queue_attr(); } else if (dqa->do_vtable != DISPATCH_VTABLE(queue_attr)) { DISPATCH_CLIENT_CRASH(dqa->do_vtable, "Invalid queue attribute" ); } dispatch_qos_t qos = _dispatch_priority_qos(dqa->dqa_qos_and_relpri); #if !HAVE_PTHREAD_WORKQUEUE_QOS if (qos == DISPATCH_QOS_USER_INTERACTIVE) { qos = DISPATCH_QOS_USER_INITIATED; } if (qos == DISPATCH_QOS_MAINTENANCE) { qos = DISPATCH_QOS_BACKGROUND; } #endif _dispatch_queue_attr_overcommit_t overcommit = dqa->dqa_overcommit; if (overcommit != _dispatch_queue_attr_overcommit_unspecified && tq) { if (tq->do_targetq) { DISPATCH_CLIENT_CRASH(tq, "Cannot specify both overcommit and " "a non-global target queue" ); } } if (tq && !tq->do_targetq && tq->do_ref_cnt == DISPATCH_OBJECT_GLOBAL_REFCNT) { if (overcommit == _dispatch_queue_attr_overcommit_unspecified) { if (tq->dq_priority & DISPATCH_PRIORITY_FLAG_OVERCOMMIT) { overcommit = _dispatch_queue_attr_overcommit_enabled; } else { overcommit = _dispatch_queue_attr_overcommit_disabled; } } if (qos == DISPATCH_QOS_UNSPECIFIED) { dispatch_qos_t tq_qos = _dispatch_priority_qos(tq->dq_priority); tq = _dispatch_get_root_queue(tq_qos, overcommit == _dispatch_queue_attr_overcommit_enabled); } else { tq = NULL ; } } else if (tq && !tq->do_targetq) { if (overcommit != _dispatch_queue_attr_overcommit_unspecified) { DISPATCH_CLIENT_CRASH(tq, "Cannot specify an overcommit attribute " "and use this kind of target queue" ); } if (qos != DISPATCH_QOS_UNSPECIFIED) { DISPATCH_CLIENT_CRASH(tq, "Cannot specify a QoS attribute " "and use this kind of target queue" ); } } else { if (overcommit == _dispatch_queue_attr_overcommit_unspecified) { overcommit = dqa->dqa_concurrent ? _dispatch_queue_attr_overcommit_disabled : _dispatch_queue_attr_overcommit_enabled; } } if (!tq) { tq = _dispatch_get_root_queue( qos == DISPATCH_QOS_UNSPECIFIED ? DISPATCH_QOS_DEFAULT : qos, overcommit == _dispatch_queue_attr_overcommit_enabled); if (slowpath(!tq)) { DISPATCH_CLIENT_CRASH(qos, "Invalid queue attribute" ); } } if (legacy) { if (dqa->dqa_inactive || dqa->dqa_autorelease_frequency) { legacy = false ; } } const void *vtable; dispatch_queue_flags_t dqf = 0 ; if (legacy) { vtable = DISPATCH_VTABLE(queue ); } else if (dqa->dqa_concurrent) { vtable = DISPATCH_VTABLE(queue_concurrent); } else { vtable = DISPATCH_VTABLE(queue_serial); } switch (dqa->dqa_autorelease_frequency) { case DISPATCH_AUTORELEASE_FREQUENCY_NEVER: dqf |= DQF_AUTORELEASE_NEVER; break ; case DISPATCH_AUTORELEASE_FREQUENCY_WORK_ITEM: dqf |= DQF_AUTORELEASE_ALWAYS; break ; } if (legacy) { dqf |= DQF_LEGACY; } if (label) { const char *tmp = _dispatch_strdup_if_mutable(label); if (tmp != label) { dqf |= DQF_LABEL_NEEDS_FREE; label = tmp; } } dispatch_queue_t dq = _dispatch_object_alloc(vtable, sizeof (struct dispatch_queue_s) - DISPATCH_QUEUE_CACHELINE_PAD); _dispatch_queue_init(dq, dqf, dqa->dqa_concurrent ? DISPATCH_QUEUE_WIDTH_MAX : 1 , DISPATCH_QUEUE_ROLE_INNER | (dqa->dqa_inactive ? DISPATCH_QUEUE_INACTIVE : 0 )); dq->dq_label = label; #if HAVE_PTHREAD_WORKQUEUE_QOS dq->dq_priority = dqa->dqa_qos_and_relpri; if (overcommit == _dispatch_queue_attr_overcommit_enabled) { dq->dq_priority |= DISPATCH_PRIORITY_FLAG_OVERCOMMIT; } #endif _dispatch_retain(tq); if (qos == QOS_CLASS_UNSPECIFIED) { _dispatch_queue_priority_inherit_from_target(dq, tq); } if (!dqa->dqa_inactive) { _dispatch_queue_inherit_wlh_from_target(dq, tq); } dq->do_targetq = tq; _dispatch_object_debug(dq, "%s" , __func__); return _dispatch_introspection_queue_create(dq); }
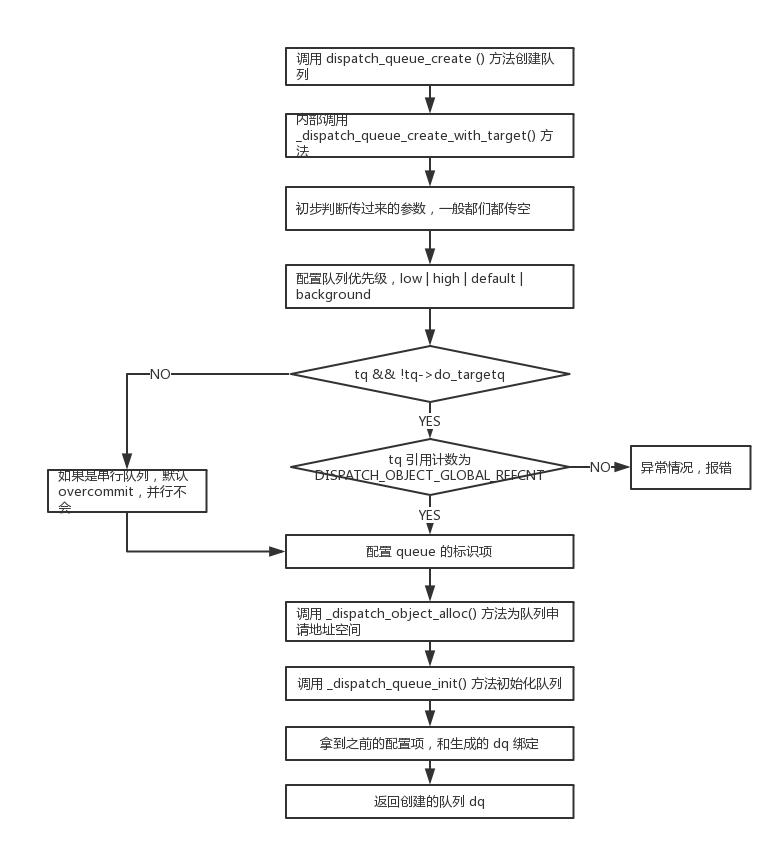
根据代码生成的流程图,不想看代码直接看图,下同:
根据流程图,这个方法的步骤如下:
开发者调用 dispatch_queue_create() 方法之后,内部会调用 _dispatch_queue_create_with_target() 方法。
然后进行初步判断,多数情况下,我们是不会传队列类型的,都是穿 NULL,所以这里是个 slowpath。如果传了参数,但是不是规定的队列类型,系统会认为你是个智障,并抛出错误。
然后初始化一些配置项。主要是 target_queue,overcommit 项和 qos。target_queue 是依赖的目标队列,像任何队列提交的任务(block),最终都会放到目标队列中执行;支持 overcommit 时,每当想队列提交一个任务时,都会开一个新的线程处理,这样是为了避免单一线程任务太多而过载;qos 是队列优先级,之前已经说过。
然后进入判断分支。普通的串行队列的目标队列,就是一个支持 overcommit 的全局队列(对应 else 分支);当前 tq 对象的引用计数为 DISPATCH_OBJECT_GLOBAL_REFCNT (永远不会释放)时,且还没有目标队列时,才可以设置 overcommit 项,而且当优先级为 DISPATCH_QOS_UNSPECIFIED 时,需要重置 tq (对应 if 分支);其他情况(else if 分支)。
然后配置队列的标识,以方便在调试时找到自己的那个队列。
使用 _dispatch_object_alloc 方法申请一个 dispatch_queue_t 对象空间,dq。
根据传入的信息(并行 or 串行;活跃 or 非活跃)来初始化这个队列。并行队列的 width 会设置为 DISPATCH_QUEUE_WIDTH_MAX 即最大,不设限;串行的会设置为 1。
将上面获得配置项,目标队列,是否支持 overcommit,优先级和 dq 绑定。
返回这个队列。返回去还输出了一句信息,便于调试。
异步执行
这个版本异步执行的代码,因为方法拆分很多,所以显得很乱。源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 void dispatch_async(dispatch_queue_t dq, dispatch_block_t work) { dispatch_continuation_t dc = _dispatch_continuation_alloc(); uintptr_t dc_flags = DISPATCH_OBJ_CONSUME_BIT; _dispatch_continuation_init(dc, dq, work, 0 , 0 , dc_flags); _dispatch_continuation_async(dq, dc); } DISPATCH_NOINLINE void _dispatch_continuation_async(dispatch_queue_t dq, dispatch_continuation_t dc) { _dispatch_continuation_async2(dq, dc, dc->dc_flags & DISPATCH_OBJ_BARRIER_BIT); } DISPATCH_ALWAYS_INLINE static inline void _dispatch_continuation_async2(dispatch_queue_t dq, dispatch_continuation_t dc, bool barrier) { if (fastpath(barrier || !DISPATCH_QUEUE_USES_REDIRECTION(dq->dq_width))) { return _dispatch_continuation_push(dq, dc); } return _dispatch_async_f2(dq, dc); } DISPATCH_NOINLINE static void _dispatch_async_f2(dispatch_queue_t dq, dispatch_continuation_t dc) { if (slowpath(dq->dq_items_tail)) { return _dispatch_continuation_push(dq, dc); } if (slowpath(!_dispatch_queue_try_acquire_async(dq))) { return _dispatch_continuation_push(dq, dc); } return _dispatch_async_f_redirect(dq, dc, _dispatch_continuation_override_qos(dq, dc)); } DISPATCH_NOINLINE static void _dispatch_async_f_redirect(dispatch_queue_t dq, dispatch_object_t dou, dispatch_qos_t qos) { if (!slowpath(_dispatch_object_is_redirection(dou))) { dou._dc = _dispatch_async_redirect_wrap(dq, dou); } dq = dq->do_targetq; while (slowpath(DISPATCH_QUEUE_USES_REDIRECTION(dq->dq_width))) { if (!fastpath(_dispatch_queue_try_acquire_async(dq))) { break ; } if (!dou._dc->dc_ctxt) { dou._dc->dc_ctxt = (void *) (uintptr_t )_dispatch_queue_autorelease_frequency(dq); } dq = dq->do_targetq; } dx_push(dq, dou, qos); } ... 省略一些调用层级, DISPATCH_ALWAYS_INLINE static inline void _dispatch_continuation_invoke_inline(dispatch_object_t dou, voucher_t ov, dispatch_invoke_flags_t flags) { dispatch_continuation_t dc = dou._dc, dc1; dispatch_invoke_with_autoreleasepool(flags, { uintptr_t dc_flags = dc->dc_flags; _dispatch_continuation_voucher_adopt(dc, ov, dc_flags); if (dc_flags & DISPATCH_OBJ_CONSUME_BIT) { dc1 = _dispatch_continuation_free_cacheonly(dc); } else { dc1 = NULL ; } if (unlikely(dc_flags & DISPATCH_OBJ_GROUP_BIT)) { _dispatch_continuation_with_group_invoke(dc); } else { _dispatch_client_callout(dc->dc_ctxt, dc->dc_func); _dispatch_introspection_queue_item_complete(dou); } if (unlikely(dc1)) { _dispatch_continuation_free_to_cache_limit(dc1); } }); _dispatch_perfmon_workitem_inc(); }
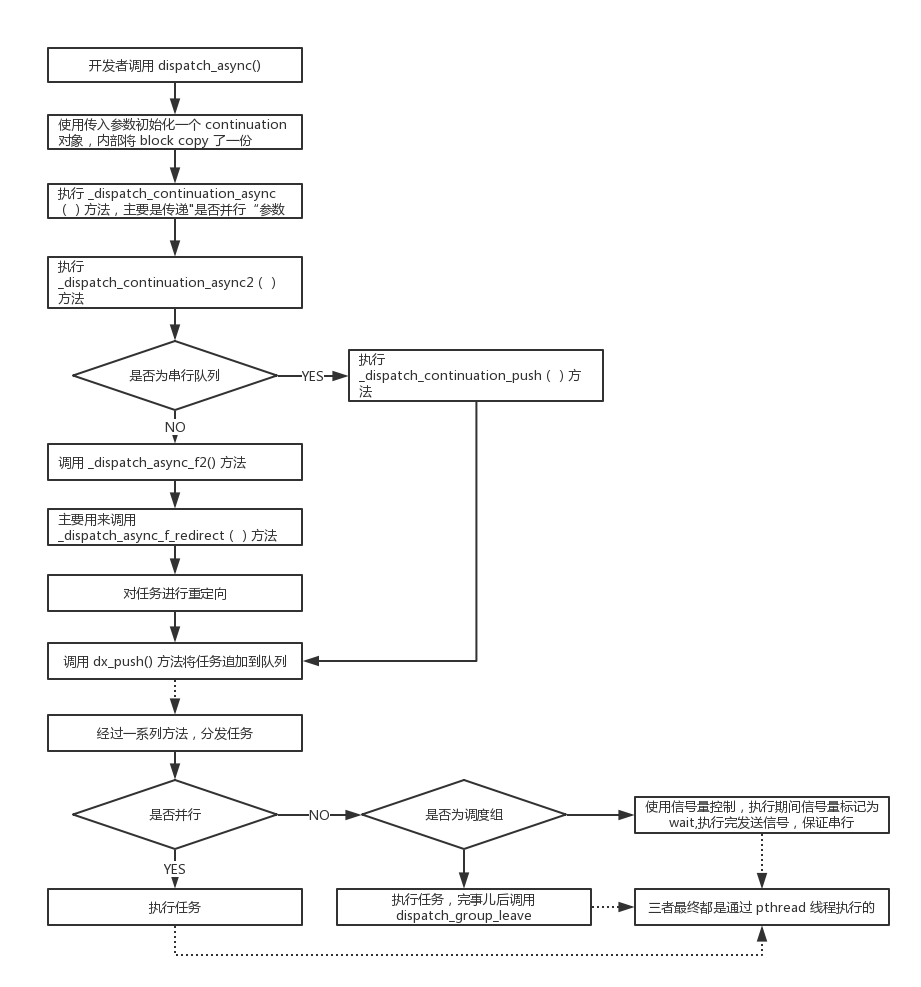
不想看代码,直接看图:
根据流程图描述一下过程:
首先开发者调用 dispatch_async() 方法,然后内部创建了一个 _dispatch_continuation_init 队列,将 queue、block 这些信息和这个 dc 绑定起来。这过程中 copy 了 block。
然后经过了几个层次的调用,主要为了区分并行还是串行。
如果是串行(这种情况比较常见,所以是 fastpath),直接就 dx_push 了,其实就是讲任务追加到一个链表里面。
如果是并行,需要做重定向。之前我们说过,放到队列中的任务,最终都会以各种形式追加到目标队列里面。在 _dispatch_async_f_redirect 方法中,重新寻找依赖目标队列,然后追加过去。
经过一系列调用,我们会在 _dispatch_continuation_invoke_inline 方法里区分串行还是并行。因为这个方法会被频繁调用,所以定义成了内联函数。对于串行队列,我们使用信号量控制,执行前信号量置为 wait,执行完毕后发送 singal;对于调度组,我们会在执行完之后调用 dispatch_group_leave。
底层的线程池,是使用 pthread 维护的,所以最终都会使用 pthread 来处理这些任务。
同步执行
同步执行,相对来说比较简单,源码如下 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 void dispatch_sync(dispatch_queue_t dq, dispatch_block_t work) { if (unlikely(_dispatch_block_has_private_data(work))) { return _dispatch_sync_block_with_private_data(dq, work, 0 ); } dispatch_sync_f(dq, work, _dispatch_Block_invoke(work)); } DISPATCH_NOINLINE void dispatch_sync_f(dispatch_queue_t dq, void *ctxt, dispatch_function_t func) { if (likely(dq->dq_width == 1 )) { return dispatch_barrier_sync_f(dq, ctxt, func); } if (unlikely(!_dispatch_queue_try_reserve_sync_width(dq))) { return _dispatch_sync_f_slow(dq, ctxt, func, 0 ); } _dispatch_introspection_sync_begin(dq); if (unlikely(dq->do_targetq->do_targetq)) { return _dispatch_sync_recurse(dq, ctxt, func, 0 ); } _dispatch_sync_invoke_and_complete(dq, ctxt, func); }
同步执行,相对来说简单些,大体逻辑差不多。偷懒一下,就不画图了,直接描述:
开发者使用 dispatch_sync() 方法,大多数路径,都会调用 dispatch_sync_f() 方法。
如果是串行队列,则通过 dispatch_barrier_sync_f() 方法来保证原子操作。
如果不是串行的(一般很少),我们使用 _dispatch_introspection_sync_begin 和 _dispatch_sync_invoke_and_complete 来保证同步。
dispatch_after dispatch_after 一般用于延后执行一些任务,可以用来代替 NSTimer,因为有时候 NSTimer 问题太多了。在后面的一章里,我会总体讲一下多线程中的问题,这里就不详细说了。一般我们这样来使用 dispatch_after :
1 2 3 4 5 6 7 - (void )viewDidLoad { [super viewDidLoad]; dispatch_queue_t queue = dispatch_queue_create("com.bool.dispatch" , DISPATCH_QUEUE_SERIAL); dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(NSEC_PER_SEC * 2.0 f)),queue, ^{ }); }
在做页面过渡时,刚进入到新的页面我们并不会立即更新一些 view,为了引起用户注意,我们会过会儿再进行更新,可以中此 API 来完成。
源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 DISPATCH_ALWAYS_INLINE static inline void _dispatch_after(dispatch_time_t when, dispatch_queue_t queue , void *ctxt, void *handler, bool block) { dispatch_timer_source_refs_t dt; dispatch_source_t ds; uint64_t leeway, delta; if (when == DISPATCH_TIME_FOREVER) { #if DISPATCH_DEBUG DISPATCH_CLIENT_CRASH(0 , "dispatch_after called with 'when' == infinity" ); #endif return ; } delta = _dispatch_timeout(when); if (delta == 0 ) { if (block) { return dispatch_async(queue , handler); } return dispatch_async_f(queue , ctxt, handler); } leeway = delta / 10 ; if (leeway < NSEC_PER_MSEC) leeway = NSEC_PER_MSEC; if (leeway > 60 * NSEC_PER_SEC) leeway = 60 * NSEC_PER_SEC; ds = dispatch_source_create(&_dispatch_source_type_after, 0 , 0 , queue ); dt = ds->ds_timer_refs; dispatch_continuation_t dc = _dispatch_continuation_alloc(); if (block) { _dispatch_continuation_init(dc, ds, handler, 0 , 0 , 0 ); } else { _dispatch_continuation_init_f(dc, ds, ctxt, handler, 0 , 0 , 0 ); } dc->dc_data = ds; _dispatch_trace_continuation_push(ds->_as_dq, dc); os_atomic_store2o(dt, ds_handler[DS_EVENT_HANDLER], dc, relaxed); if ((int64_t )when < 0 ) { when = (dispatch_time_t )-((int64_t )when); } else { dt->du_fflags |= DISPATCH_TIMER_CLOCK_MACH; leeway = _dispatch_time_nano2mach(leeway); } dt->dt_timer.target = when; dt->dt_timer.interval = UINT64_MAX; dt->dt_timer.deadline = when + leeway; dispatch_activate(ds); }
dispatch_after() 内部会调用 _dispatch_after() 方法,然后先判断延迟时间。如果为 DISPATCH_TIME_FOREVER(永远不执行),则会出现异常;如果为 0 则立即执行;否则的话会创建一个 dispatch_timer_source_refs_t 结构体指针,将上下文相关信息与之关联。然后使用 dispatch_source 相关方法,将定时器和 block 任务关联起来。定时器时间到时,取出 block 任务开始执行。
dispatch_once 如果我们有一段代码,在 App 生命周期内最好只初始化一次,这时候使用 dispatch_once 最好不过了。例如我们单例中经常这样用:
1 2 3 4 5 6 7 8 9 + (instancetype )sharedManager { static BLDispatchManager *sharedInstance = nil ; static dispatch_once_t onceToken; dispatch_once (&onceToken, ^{ sharedInstance = [[BLDispatchManager alloc] initPrivate]; }); return sharedInstance; }
还有在定义 NSDateFormatter 时使用:
1 2 3 4 5 6 7 8 9 10 11 12 - (NSString *)todayDateString { static NSDateFormatter *formatter = nil ; static dispatch_once_t onceToken; dispatch_once (&onceToken, ^{ formatter = [NSDateFormatter new]; formatter.locale = [NSLocale localeWithLocaleIdentifier:@"en_US_POSIX" ]; formatter.timeZone = [NSTimeZone timeZoneForSecondsFromGMT:8 * 3600 ]; formatter.dateFormat = @"yyyyMMdd" ; }); return [formatter stringFromDate:[NSDate date]]; }
因为这是很常用的一个代码片段,所以被加在了 Xcode 的 code snippet 中。
它的源代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 typedef struct _dispatch_once_waiter_s { volatile struct _dispatch_once_waiter_s *volatile dow_next ; dispatch_thread_event_s dow_event; mach_port_t dow_thread; } *_dispatch_once_waiter_t ; void dispatch_once(dispatch_once_t *val, dispatch_block_t block) { dispatch_once_f(val, block, _dispatch_Block_invoke(block)); } DISPATCH_NOINLINE void dispatch_once_f(dispatch_once_t *val, void *ctxt, dispatch_function_t func) { #if !DISPATCH_ONCE_INLINE_FASTPATH if (likely(os_atomic_load(val, acquire) == DLOCK_ONCE_DONE)) { return ; } #endif return dispatch_once_f_slow(val, ctxt, func); } DISPATCH_ONCE_SLOW_INLINE static void dispatch_once_f_slow(dispatch_once_t *val, void *ctxt, dispatch_function_t func) { #if DISPATCH_GATE_USE_FOR_DISPATCH_ONCE dispatch_once_gate_t l = (dispatch_once_gate_t )val; if (_dispatch_once_gate_tryenter(l)) { _dispatch_client_callout(ctxt, func); _dispatch_once_gate_broadcast(l); } else { _dispatch_once_gate_wait(l); } #else _dispatch_once_waiter_t volatile *vval = (_dispatch_once_waiter_t *)val; struct _dispatch_once_waiter_s dow = { _dispatch_once_waiter_t tail = &dow, next, tmp; dispatch_thread_event_t event; if (os_atomic_cmpxchg(vval, NULL , tail, acquire)) { dow.dow_thread = _dispatch_tid_self(); _dispatch_client_callout(ctxt, func); next = (_dispatch_once_waiter_t )_dispatch_once_xchg_done(val); while (next != tail) { tmp = (_dispatch_once_waiter_t )_dispatch_wait_until(next->dow_next); event = &next->dow_event; next = tmp; _dispatch_thread_event_signal(event); } } else { _dispatch_thread_event_init(&dow.dow_event); next = *vval; for (;;) { if (next == DISPATCH_ONCE_DONE) { break ; } if (os_atomic_cmpxchgv(vval, next, tail, &next, release)) { dow.dow_thread = next->dow_thread; dow.dow_next = next; if (dow.dow_thread) { pthread_priority_t pp = _dispatch_get_priority(); _dispatch_thread_override_start(dow.dow_thread, pp, val); } _dispatch_thread_event_wait(&dow.dow_event); if (dow.dow_thread) { _dispatch_thread_override_end(dow.dow_thread, val); } break ; } } _dispatch_thread_event_destroy(&dow.dow_event); } #endif }
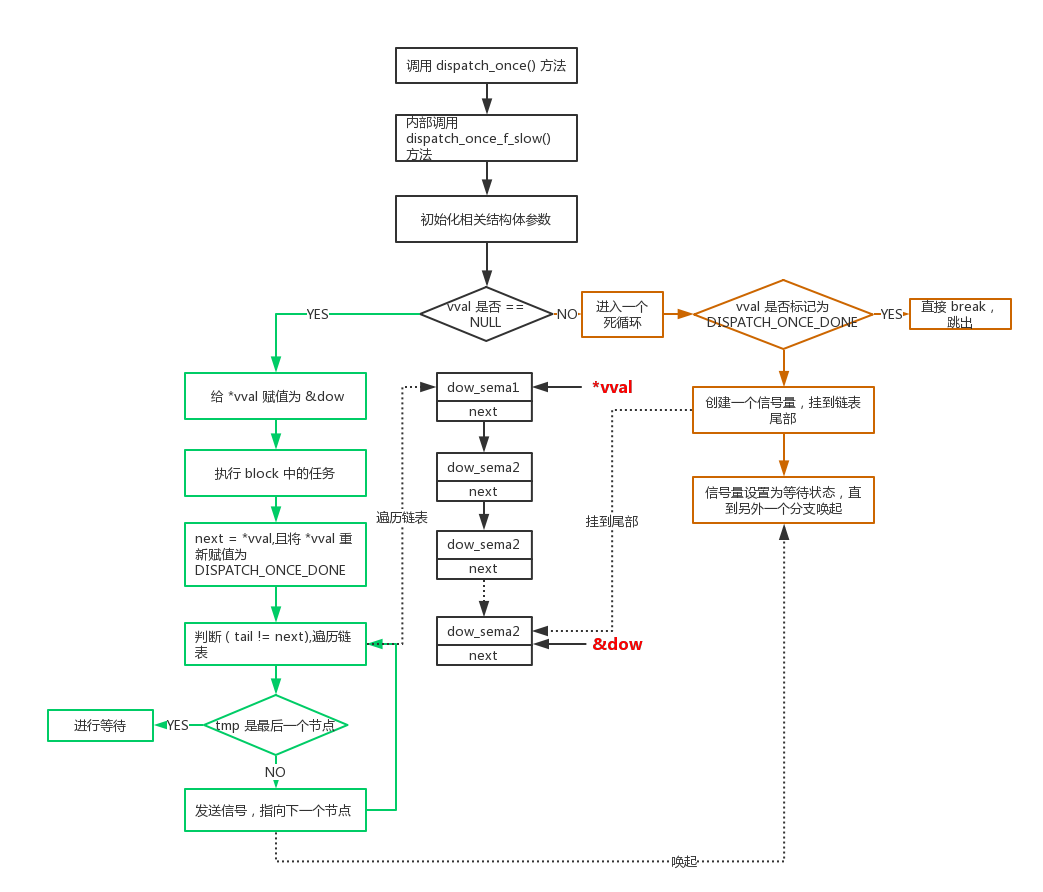
不想看代码直接看图 (emmm… 根据逻辑画完图才发现,其实这个图也挺乱的,所以我将两个主分支用不同颜色标记处理):
根据这个图,我来表述一下主要过程:
我们初始化的 once_token,也就是 *vval 实际是 0,所以第一次执行时是返回 true 的。if() 中的这个方法是原子操作,也就是说,如果多个线程同时调用这个方法,只有一个线程会进入 true 的分支,其他都进入 else 分支。
这里先说进入 true 分支。进入之后,会执行对应的 block,也就是对应的任务。然后 next 指向 vval, vval 标记为 DISPATCH_ONCE_DONE,即执行的是这样一个过程:
1 2 3 4 next = (_dispatch_once_waiter_t )_dispatch_once_xchg_done(val); next = *vval; *vval = DISPATCH_ONCE_DONE;
然后 tail = &dow。此时我们发现,原来的 *vval = &dow -> next = *vval,实际则是 next = &dow,如果没有其他线程(或者调用)进入 else 分支,&dow 实际没有改变,即 tail == tmp 。此时 while (tail != tmp) 是不会执行的,分支结束。
如果有其他线程(或者调用)进入了 else 分支,那么就已经生成了一个等待响应的链表。此时进入 &dow 已经改变,成为了链表尾部,*vval 是链表头部。进入 while 循环后,开始遍历链表,依次发送信号进行唤起。
然后说进入 else 分支的这些调用。进入分支后,随即进入一个死循环,直到发现 *vval 已经标记为了 DISPATCH_ONCE_DONE 才跳出循环。
发现 *vval 不是 DISPATCH_ONCE_DONE 之后,会将这个节点追加到链表尾部,并调用信号量的 wait 方法,等待被唤起。
以上为全部的执行过程。通过源码可以看出,使用的是 原子操作 + 信号量来保证 block 只会被执行多次,哪怕是在多线程情况下。
这样一个关于 dispatch_once 递归调用会产生死锁的现象,也就很好解释了。看下面代码:
1 2 3 4 5 6 - (void )dispatchOnceTest { static dispatch_once_t onceToken; dispatch_once (&onceToken, ^{ [self dispatchOnceTest]; }); }
通过上面分析,在 block 执行完,并将 *vval 置为 DISPATCH_ONCE_DONE 之前,其他的调用都会进入 else 分支。第二次递归调用,信号量处于等待状态,需要等到第一个 block 执行完才能被唤起;但是第一个 block 所执行的内容就是进行第二次调用,这个任务被 wait 了,也即是说 block 永远执行不完。死锁就这样发生了。
dispatch_apply 有时候没有时序性依赖的时候,我们会用 dispatch_apply 来代替 for loop。例如我们下载一组图片:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 - (void )downloadImages:(NSArray <NSURL *> *)imageURLs { for (NSURL *imageURL in imageURLs) { [self downloadImageWithURL:imageURL]; } } - (void )downloadImages:(NSArray <NSURL *> *)imageURLs { dispatch_queue_t downloadQueue = dispatch_queue_create("com.bool.download" , DISPATCH_QUEUE_CONCURRENT); dispatch_apply(imageURLs.count, downloadQueue, ^(size_t index) { NSURL *imageURL = imageURLs[index]; [self downloadImageWithURL:imageURL]; }); }
进行替换是需要注意几个问题:
任务之间没有时序性依赖,谁先执行都可以。
一般在并发队列,并发执行任务时,才替换。串行队列替换没有意义。
如果数组中数据很少,或者每个任务执行时间很短,替换也没有意义。强行进行并发的消耗,可能比使用 for loop 还要多,并不能得到优化。
至于原理,就不大篇幅讲了。大概是这个样子:这个方法是同步的,会阻塞当前线程,直到所有的 block 任务都完成。如果提交到并发队列,每个任务执行顺序是不一定的。
更多时候,我们执行下载任务,并不希望阻塞当前线程,这时我们可以使用 dispatch_group。
dispatch_group 当处理批量异步任务时,dispatch_group 是一个很好的选择。针对上面说的下载图片的例子,我们可以这样做:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 - (void )downloadImages:(NSArray <NSURL *> *)imageURLs { dispatch_group_t taskGroup = dispatch_group_create(); dispatch_queue_t queue = dispatch_queue_create("com.bool.group" , DISPATCH_QUEUE_CONCURRENT); for (NSURL *imageURL in imageURLs) { dispatch_group_enter(taskGroup); [self downloadImageWithURL:imageURL withQueue:queue completeHandler:^{ dispatch_group_leave(taskGroup); }]; } dispatch_group_notify(taskGroup, queue, ^{ }); dispatch_group_async(taskGroup, queue, ^{ }) }
关于原理方面,和 dispatch_async() 方法类似,前面也提到。这里只说一段代码:
1 2 3 4 5 6 7 8 9 DISPATCH_ALWAYS_INLINE static inline void _dispatch_continuation_group_async(dispatch_group_t dg, dispatch_queue_t dq, dispatch_continuation_t dc) { dispatch_group_enter(dg); dc->dc_data = dg; _dispatch_continuation_async(dq, dc); }
这段代码中,调用了 dispatch_group_enter(dg) 方法进行标记,最终都会和 dispatch_async() 走到同样的方法里 _dispatch_continuation_invoke_inline()。在里面判断类型为 group,执行 task,执行结束后调用 dispatch_group_leave((dispatch_group_t)dou),和之前的 enter 对应。
以上是 Dispatch Queues 内容的介绍,我们平时使用 GCD 的过程中,60% 都是使用的以上内容。
2. Dispatch Block 在 iOS 8 中,Apple 为我们提供了新的 API,Dispatch Block 相关。虽然之前我们可以向 dispatch 传递 block 参数,作为任务,但是这里和之前的不一样。之前经常说,使用 NSOperation 创建的任务可以 cancel,使用 GCD 不可以。但是在 iOS 8 之后,可以 cancel 任务了。
基本使用
创建一个 block 并执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 - (void )dispatchBlockTest { dispatch_block_t dsBlock = dispatch_block_create(0 , ^{ NSLog (@"test block" ); }); dispatch_block_t dsQosBlock = dispatch_block_create_with_qos_class(0 , QOS_CLASS_USER_INITIATED, -1 , ^{ NSLog (@"test block" ); }); dispatch_async (dispatch_get_main_queue(), dsBlock); dispatch_async (dispatch_get_main_queue(), dsQosBlock); dispatch_block_perform(0 , ^{ NSLog (@"test block" ); }); }
阻塞当前任务,等 block 执行完在继续执行。
1 2 3 4 5 6 7 8 9 10 - (void )dispatchBlockTest { dispatch_queue_t queue = dispatch_queue_create("com.bool.block" , DISPATCH_QUEUE_SERIAL); dispatch_block_t dsBlock = dispatch_block_create(0 , ^{ NSLog (@"test block" ); }); dispatch_async (queue, dsBlock); dispatch_block_wait(dsBlock, DISPATCH_TIME_FOREVER); NSLog (@"block was finished" ); }
block 执行完后,收到通知,执行其他任务
1 2 3 4 5 6 7 8 9 10 11 12 - (void )dispatchBlockTest { dispatch_queue_t queue = dispatch_queue_create("com.bool.block" , DISPATCH_QUEUE_SERIAL); dispatch_block_t dsBlock = dispatch_block_create(0 , ^{ NSLog (@"test block" ); }); dispatch_async (queue, dsBlock); dispatch_block_notify(dsBlock, queue, ^{ NSLog (@"block was finished,do other thing" ); }); NSLog (@"execute first" ); }
对 block 进行 cancel 操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 - (void )dispatchBlockTest { dispatch_queue_t queue = dispatch_queue_create("com.bool.block" , DISPATCH_QUEUE_SERIAL); dispatch_block_t dsBlock1 = dispatch_block_create(0 , ^{ NSLog (@"test block1" ); }); dispatch_block_t dsBlock2 = dispatch_block_create(0 , ^{ NSLog (@"test block2" ); }); dispatch_async (queue, dsBlock1); dispatch_async (queue, dsBlock2); dispatch_block_cancel(dsBlock2); }
3. Dispatch Barriers Dispatch Barriers 可以理解为调度屏障,常用于多线程并发读写操作。例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 @interface ViewController ()@property (nonatomic , strong ) dispatch_queue_t imageQueue;@property (nonatomic , strong ) NSMutableArray *imageArray;@end @implementation ViewController - (void )viewDidLoad { [super viewDidLoad]; self .imageQueue = dispatch_queue_create("com.bool.image" , DISPATCH_QUEUE_CONCURRENT); self .imageArray = [NSMutableArray array]; } - (void )addImage:(UIImage *)image { dispatch_barrier_async(self .imageQueue, ^{ [self .imageArray addObject:image]; dispatch_async (dispatch_get_main_queue(), ^{ }); }); } - (NSArray <UIImage *> *)images { __block NSArray *imagesArray = nil ; dispatch_sync (self .imageQueue, ^{ imagesArray = [self .imageArray mutableCopy]; }); return imagesArray; } @end
转化成图可能好理解一些:
dispatch_barrier_async() 的原理和 dispatch_async() 差不多,只不过设置的 flags 不一样:
1 2 3 4 5 6 7 8 9 10 void dispatch_barrier_async(dispatch_queue_t dq, dispatch_block_t work) { dispatch_continuation_t dc = _dispatch_continuation_alloc(); uintptr_t dc_flags = DISPATCH_OBJ_CONSUME_BIT | DISPATCH_OBJ_BARRIER_BIT; _dispatch_continuation_init(dc, dq, work, 0 , 0 , dc_flags); _dispatch_continuation_push(dq, dc); }
后面都是 push 到队列中,然后,获取任务时一个死循环,在从队列中获取任务一个一个执行,如果判断 flag 为 barrier,终止循环,则单独执行这个任务。它后面的任务放入一个队列,等它执行完了再开始执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 DISPATCH_ALWAYS_INLINE static dispatch_queue_wakeup_target_t _dispatch_queue_drain(dispatch_queue_t dq, dispatch_invoke_context_t dic, dispatch_invoke_flags_t flags, uint64_t *owned_ptr, bool serial_drain) { ... for (;;) { ... first_iteration: dq_state = os_atomic_load(&dq->dq_state, relaxed); if (unlikely(_dq_state_is_suspended(dq_state))) { break ; } if (unlikely(orig_tq != dq->do_targetq)) { break ; } if (serial_drain || _dispatch_object_is_barrier(dc)) { if (!serial_drain && owned != DISPATCH_QUEUE_IN_BARRIER) { if (!_dispatch_queue_try_upgrade_full_width(dq, owned)) { goto out_with_no_width; } owned = DISPATCH_QUEUE_IN_BARRIER; } next_dc = _dispatch_queue_next(dq, dc); if (_dispatch_object_is_sync_waiter(dc)) { owned = 0 ; dic->dic_deferred = dc; goto out_with_deferred; } } else { if (owned == DISPATCH_QUEUE_IN_BARRIER) { os_atomic_xor2o(dq, dq_state, owned, release); owned = dq->dq_width * DISPATCH_QUEUE_WIDTH_INTERVAL; } else if (unlikely(owned == 0 )) { if (_dispatch_object_is_sync_waiter(dc)) { _dispatch_queue_reserve_sync_width(dq); } else if (!_dispatch_queue_try_acquire_async(dq)) { goto out_with_no_width; } owned = DISPATCH_QUEUE_WIDTH_INTERVAL; } next_dc = _dispatch_queue_next(dq, dc); if (_dispatch_object_is_sync_waiter(dc)) { owned -= DISPATCH_QUEUE_WIDTH_INTERVAL; _dispatch_sync_waiter_redirect_or_wake(dq, DISPATCH_SYNC_WAITER_NO_UNLOCK, dc); continue ; } ... }
4. Dispatch Source 关于 dispatch_source 我们使用的少之又少,他是 BSD 系统内核功能的包装,经常用来监测某些事件发生。例如监测断点的使用和取消。[这里][https://developer.apple.com/documentation/dispatch/dispatch_source_type_constants?language=objc] 介绍了可以监测的事件:
DISPATCH_SOURCE_TYPE_DATA_ADD : 自定义事件
DISPATCH_SOURCE_TYPE_DATA_OR : 自定义事件
DISPATCH_SOURCE_TYPE_MACH_RECV : MACH 端口接收事件
DISPATCH_SOURCE_TYPE_MACH_SEND : MACH 端口发送事件
DISPATCH_SOURCE_TYPE_PROC : 进程相关事件
DISPATCH_SOURCE_TYPE_READ : 文件读取事件
DISPATCH_SOURCE_TYPE_SIGNAL : 信号相关事件
DISPATCH_SOURCE_TYPE_TIMER : 定时器相关事件
DISPATCH_SOURCE_TYPE_VNODE : 文件属性修改事件
DISPATCH_SOURCE_TYPE_WRITE : 文件写入事件
DISPATCH_SOURCE_TYPE_MEMORYPRESSURE : 内存压力事件
例如我们可以通过下面代码,来监测断点的使用和取消:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @interface ViewController ()@property (nonatomic , strong ) dispatch_source_t signalSource;@property (nonatomic , assign ) dispatch_once_t signalOnceToken;@end @implementation ViewController - (void )viewDidLoad { dispatch_once (&_signalOnceToken, ^{ dispatch_queue_t queue = dispatch_get_main_queue(); self .signalSource = dispatch_source_create(DISPATCH_SOURCE_TYPE_SIGNAL, SIGSTOP, 0 , queue); if (self .signalSource) { dispatch_source_set_event_handler(self .signalSource, ^{ NSLog (@"debug test" ); }); dispatch_resume(self .signalSource); } }); }
还有 diapatch_after() 就是依赖 dispatch_source() 来实现的。我们可以自己实现一个类似的定时器:
1 2 3 4 5 6 7 8 9 10 - (void )customTimer { dispatch_source_t timerSource = dispatch_source_create(DISPATCH_SOURCE_TYPE_TIMER, 0 , 0 , DISPATCH_TARGET_QUEUE_DEFAULT); dispatch_source_set_timer(timerSource, dispatch_time(DISPATCH_TIME_NOW, 5.0 * NSEC_PER_SEC ), 2.0 * NSEC_PER_SEC , 5 ); dispatch_source_set_event_handler(timerSource, ^{ NSLog (@"dispatch source timer" ); }); self .signalSource = timerSource; dispatch_resume(self .signalSource); }
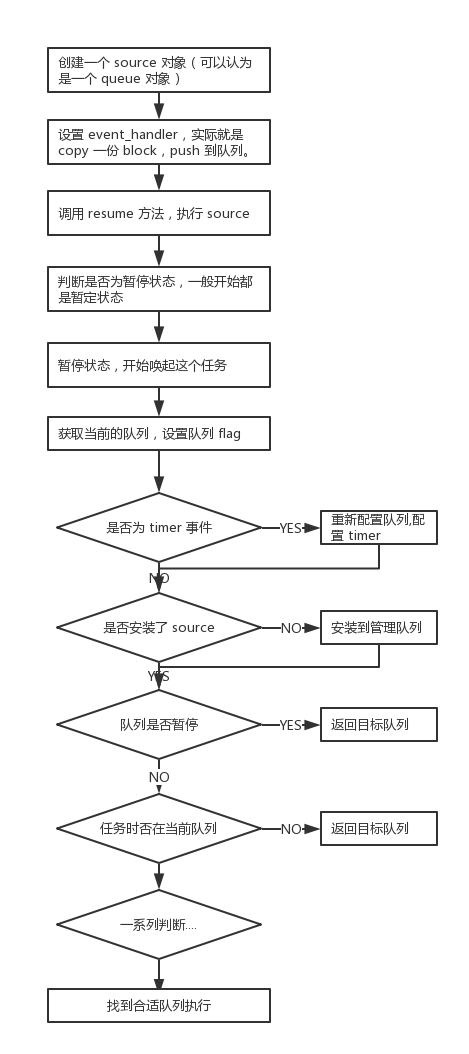
基本原理 使用 dispatch_source 时,大致过程是这样的:我们创建一个 source,然后加到队列中,并调用 dispatch_resume() 方法,便会从队列中唤起 source,执行对应的 block。下面是一个详细的流程图,我们结合这张图来说一下:
调用 resume 方法,执行 source。一般新创建的都是暂停状态,这里判断是暂停状态,就开始唤起。
1 2 3 4 5 6 7 8 void dispatch_resume(dispatch_object_t dou) { DISPATCH_OBJECT_TFB(_dispatch_objc_resume, dou); if (dx_vtable(dou._do)->do_suspend) { dx_vtable(dou._do)->do_resume(dou._do, false ); } }
最后一步,是最核心的异步,唤起任务开始执行。之前的 queue 最终也是走到这样类似的一步,可以看返回类型都是 dispatch_queue_wakeup_target_t,基本是沿着 queue 的逻辑一路 copy 过来。这个方法,经过一系列判断,保证所有的 source 都会在正确的队列上面执行;如果队列和任务不对应,那么就返回正确的队列,重新派发让任务在正确的队列上执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 DISPATCH_ALWAYS_INLINE static inline dispatch_queue_wakeup_target_t _dispatch_source_invoke2(dispatch_object_t dou, dispatch_invoke_context_t dic, dispatch_invoke_flags_t flags, uint64_t *owned) { dispatch_source_t ds = dou._ds; dispatch_queue_wakeup_target_t retq = DISPATCH_QUEUE_WAKEUP_NONE; dispatch_queue_t dq = _dispatch_queue_get_current(); dispatch_source_refs_t dr = ds->ds_refs; dispatch_queue_flags_t dqf; ... if (dr->du_is_timer && os_atomic_load2o(ds, ds_timer_refs->dt_pending_config, relaxed)) { dqf = _dispatch_queue_atomic_flags(ds->_as_dq); if (!(dqf & (DSF_CANCELED | DQF_RELEASED))) { if (dq != dkq) { return dkq; } _dispatch_source_timer_configure(ds); } } if (!ds->ds_is_installed) { if (dq != dkq) { return dkq; } _dispatch_source_install(ds, _dispatch_get_wlh(), _dispatch_get_basepri()); } if (unlikely(DISPATCH_QUEUE_IS_SUSPENDED(ds))) { return ds->do_targetq; } if (_dispatch_source_get_registration_handler(dr)) { if (dq != ds->do_targetq) { return ds->do_targetq; } _dispatch_source_registration_callout(ds, dq, flags); } ... if (!(dqf & (DSF_CANCELED | DQF_RELEASED)) && os_atomic_load2o(ds, ds_pending_data, relaxed)) { if (dq == ds->do_targetq) { _dispatch_source_latch_and_call(ds, dq, flags); dqf = _dispatch_queue_atomic_flags(ds->_as_dq); prevent_starvation = dq->do_targetq || !(dq->dq_priority & DISPATCH_PRIORITY_FLAG_OVERCOMMIT); if (prevent_starvation && os_atomic_load2o(ds, ds_pending_data, relaxed)) { retq = ds->do_targetq; } } else { return ds->do_targetq; } } if ((dqf & (DSF_CANCELED | DQF_RELEASED)) && !(dqf & DSF_DEFERRED_DELETE)) { if (!(dqf & DSF_DELETED)) { if (dr->du_is_timer && !(dqf & DSF_ARMED)) { } else if (dq != dkq) { return dkq; } _dispatch_source_refs_unregister(ds, 0 ); dqf = _dispatch_queue_atomic_flags(ds->_as_dq); if (unlikely(dqf & DSF_DEFERRED_DELETE)) { if (!(dqf & DSF_ARMED)) { goto unregister_event; } return retq ? retq : DISPATCH_QUEUE_WAKEUP_WAIT_FOR_EVENT; } } if (dq != ds->do_targetq && (_dispatch_source_get_event_handler(dr) || _dispatch_source_get_cancel_handler(dr) || _dispatch_source_get_registration_handler(dr))) { retq = ds->do_targetq; } else { _dispatch_source_cancel_callout(ds, dq, flags); dqf = _dispatch_queue_atomic_flags(ds->_as_dq); } prevent_starvation = false ; } if (_dispatch_unote_needs_rearm(dr) && !(dqf & (DSF_ARMED|DSF_DELETED|DSF_CANCELED|DQF_RELEASED))) { if (dq != dkq) { return dkq; } if (unlikely(dqf & DSF_DEFERRED_DELETE)) { goto unregister_event; } if (unlikely(DISPATCH_QUEUE_IS_SUSPENDED(ds))) { return ds->do_targetq; } if (prevent_starvation && dr->du_wlh == DISPATCH_WLH_ANON) { return ds->do_targetq; } if (unlikely(!_dispatch_source_refs_resume(ds))) { goto unregister_event; } if (!prevent_starvation && _dispatch_wlh_should_poll_unote(dr)) { _dispatch_event_loop_drain(KEVENT_FLAG_IMMEDIATE); } } return retq; }
还有一些其他的方法,这里就不介绍了。有兴趣的可以看源码,太多了。
5. Dispatch I/O 我们可以使用 Dispatch I/O 快速读取一些文件,例如这样 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 - (void )readFile { NSString *filePath = @"/.../青花瓷.m" ; dispatch_queue_t queue = dispatch_queue_create("com.bool.readfile" , DISPATCH_QUEUE_SERIAL); dispatch_fd_t fd = open(filePath.UTF8String, O_RDONLY,0 ); dispatch_io_t fileChannel = dispatch_io_create(DISPATCH_IO_STREAM, fd, queue, ^(int error) { close(fd); }); NSMutableData *fileData = [NSMutableData new]; dispatch_io_set_low_water(fileChannel, SIZE_MAX); dispatch_io_read(fileChannel, 0 , SIZE_MAX, queue, ^(bool done, dispatch_data_t _Nullable data, int error) { if (error == 0 && dispatch_data_get_size(data) > 0 ) { [fileData appendData:(NSData *)data]; } if (done) { NSString *str = [[NSString alloc] initWithData:fileData encoding:NSUTF8StringEncoding ]; NSLog (@"read file completed, string is :\n %@" ,str); } }); }
输出结果:
1 2 3 ConcurrencyTest[41479 :5357296 ] read file completed, string is : 天青色等烟雨 而我在等你 月色被打捞起 晕开了结局
如果读取大文件,我们可以进行切片读取,将文件分割多个片,放在异步线程中并发执行,这样会比较快一些。
关于源码,简单看了一下,调度逻辑和之前的任务类似。然后读写操作,是调用的一些底层接口实现,这里就偷懒一下不详细说了。使用 Dispatch I/O,多数情况下是为了并发读取一个大文件,提高读取速度。
6. Other 上面已经讲了概览图中的大部分东西,还有一些未讲述,这里简单描述一下:
dispatch_object。GCD 用 C 函数实现的对象,不能通过集成 dispatch 类实现,也不能用 alloc 方法初始化。GCD 针对 dispatch_object 提供了一些接口,我们使用这些接口可以处理一些内存事件、取消和暂停操作、定义上下文和处理日志相关工作。dispatch_object 必须要手动管理内存,不遵循垃圾回收机制。
dispatch_time。在 GCD 中使用的时间对象,可以创建自定义时间,也可以使用 DISPATCH_TIME_NOW、DISPATCH_TIME_FOREVER 这两个系统给出的时间。
以上为 GCD 相关知识,这次使用的源码版本为最新版本 —— 912.30.4.tar.gz ,和之前看的版本代码差距很大,因为代码量的增加,新版本代码比较乱,不过基本原理还是差不多的。曾经我一度认为,最上面的是最新版本…
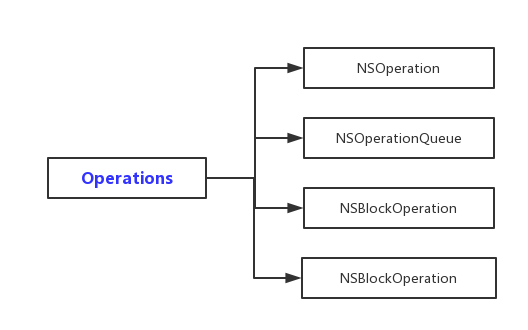
Operations Operations 也是我们在并发编程中常用的一套 API,根据 官方文档 划分的结构如下图:
其中 NSBlockOperation 和 NSInvocationOperation 是基于 NSOperation 的子类化实现。相对于 GCD,Operations 的原理要稍微好理解一些,下面就将用法和原理介绍一下。
1. NSOperation 基本使用 每一个 operation 可以认为是一个 task。NSOperation 本事是一个抽象类,使用前需子类化。幸运的是,Apple 为我们实现了两个子类:NSInvocationOperation、NSBlockOperation。我们也可以自己去定义一个 operation。下面介绍一下基本使用:
创建一个 NSInvocationOperation 对象并在当前线程执行.
1 2 NSInvocationOperation *invocationOperation = [[NSInvocationOperation alloc] initWithTarget:self selector:@selector (log) object:nil ]; [invocationOperation start];
创建一个 NSBlockOperation 对象并执行 (每个 block 不一定会在当前线程,也不一定在同一线程执行).
1 2 3 4 5 6 7 8 9 NSBlockOperation *blockOpeartion = [NSBlockOperation blockOperationWithBlock:^{ NSLog (@"block operation" ); }]; [blockOpeartion addExecutionBlock:^{ NSLog (@"other block opeartion" ); }]; [blockOpeartion start];
自定义一个 Operation。当我们不需要操作状态的时候,只需要实现 main() 方法即可。需要操作状态的后面再说.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @interface BLOpeartion : NSOperation @end @implementation BLOpeartion - (void )main { NSLog (@"BLOperation main method" ); } @end - (void )viewDidLoad { [super viewDidLoad]; BLOperation *blOperation = [BLOperation new]; [blOperation start]; }
每个 operation 之间设置依赖.
1 2 3 4 5 6 7 8 NSBlockOperation *blockOpeartion1 = [NSBlockOperation blockOperationWithBlock:^{ NSLog (@"block operation1" ); }]; NSBlockOperation *blockOpeartion2 = [NSBlockOperation blockOperationWithBlock:^{ NSLog (@"block operation2" ); }]; [blockOpeartion2 addDependency:blockOpeartion1];
与队列相关的使用,后面再说.
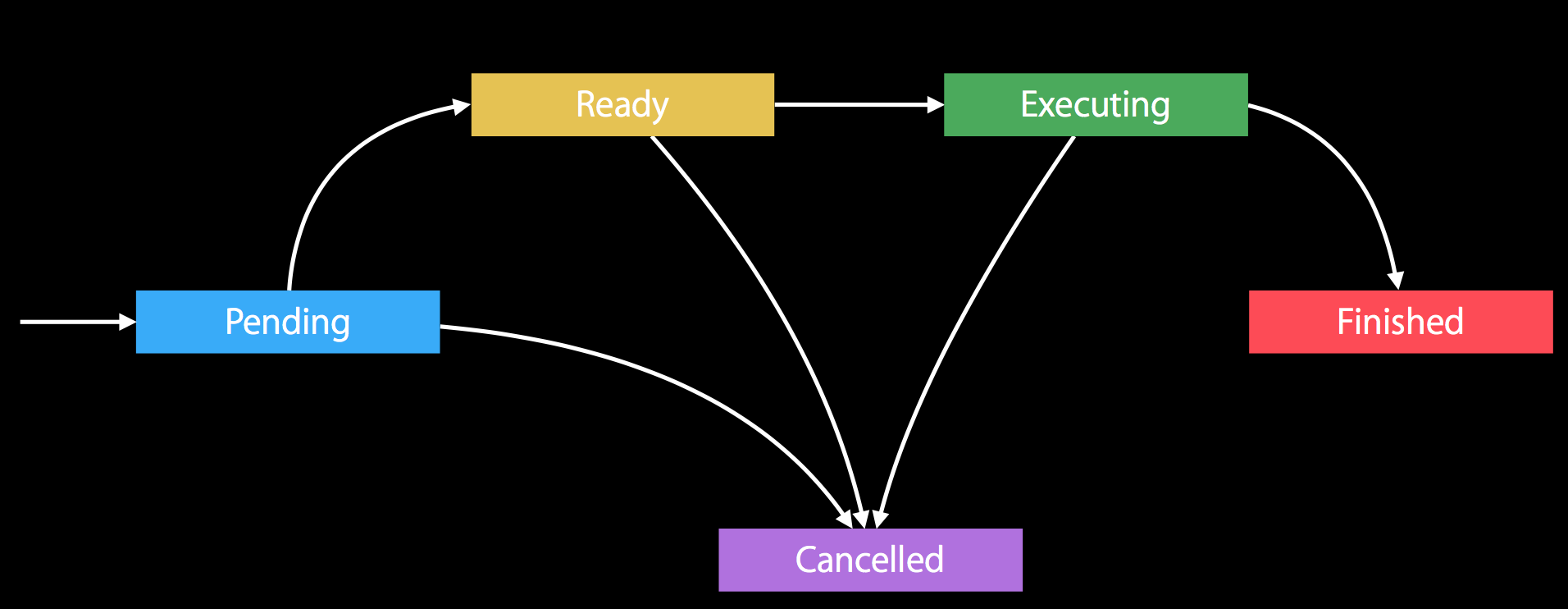
基本原理 NSOperation 内置了一个强大的状态机,一个 operation 从初始化到执行完毕这一生命周期,对应了各种状态。下面是在 WWDC 2015 Advanced NSOperations 出现的一张图:
operation 一开始是 Pending 状态,代表即将进入 Ready;进入 Ready 之后,代表任务可以执行;然后进入 Executing 状态;最后执行完成,进入 Finished 状态。过程中,除了 Finished 状态,在其他几个状态中都可以进行 Cancelled。
NSOperation 并没有开源。但是 swift 开源了,在 swift 中它叫 Opeartion,我们可以在 这里 找到他的源码。我这里 copy 了一份:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 open class Operation : NSObject let lock = NSLock () internal weak var _queue: OperationQueue ? internal var _cancelled = false internal var _executing = false internal var _finished = false internal var _ready = false internal var _dependencies = Set <Operation >() #if DEPLOYMENT_ENABLE_LIBDISPATCH internal var _group = DispatchGroup () internal var _depGroup = DispatchGroup () internal var _groups = [DispatchGroup ]() #endif public override init () { super .init () #if DEPLOYMENT_ENABLE_LIBDISPATCH _group.enter() #endif } internal func _leaveGroups() #if DEPLOYMENT_ENABLE_LIBDISPATCH _groups.forEach() { $0 .leave() } _groups.removeAll() _group.leave() #endif } open func start () if !isCancelled { lock.lock() _executing = true lock.unlock() main() lock.lock() _executing = false lock.unlock() } finish() } internal func finish () lock.lock() _finished = true _leaveGroups() lock.unlock() if let queue = _queue { queue._operationFinished(self ) } ... } open func main () open func cancel () lock.lock() _cancelled = true lock.unlock() } ... open var isAsynchronous: Bool { return false } open func addDependency (_ op: Operation) lock.lock() _dependencies.insert(op) op.lock.lock() #if DEPLOYMENT_ENABLE_LIBDISPATCH _depGroup.enter() op._groups.append(_depGroup) #endif op.lock.unlock() lock.unlock() } ... open var queuePriority: QueuePriority = .normal public var completionBlock: (() -> Void )? open func waitUntilFinished () #if DEPLOYMENT_ENABLE_LIBDISPATCH _group.wait() #endif } open var threadPriority: Double = 0.5 open var qualityOfService: QualityOfService = .default open var name: String ? internal func _waitUntilReady() #if DEPLOYMENT_ENABLE_LIBDISPATCH _depGroup.wait() #endif _ready = true } }
代码很简单,具体过程可以直接看注释,就不另说了。除此之外,我们可以看出,Operation 总很多方法造作都加了锁,说明这个类是线程安全的,当我们对 NSOperation 进行子类化时,重写方法要注意线程暗转问题。
2. NSOperationQueue NSOperation 的很多花式操作,都是结合着 NSOperationQueue 进行的。我们在使用的时候,也是两者结合着使用。下面对其进行详细分析。
基本用法
operation 放到 queue 中不用在手动调用 start 方法去执行,operation 会自动执行。
queue 可以设置最大并发数,当并发数量设置为 1 时,为串行队列;默认并发数量为无限大。
queue 可以通过设置 suspended 属性来暂停或者启动还未执行的 operation 。
queue 可以通过调用 -[cancelAllOperations] 方法来取消队列中的任务。
queue 可以通过 mainQueue 方法来回到主队列(主线程);可以通过 currentQueue 方法来获取当前队列。
更多方法,请参考 官方文档
使用例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 - (void )testOperationQueue { NSOperationQueue *operationQueue = [NSOperationQueue new]; [operationQueue setMaxConcurrentOperationCount:3 ]; NSInvocationOperation *invocationOpeartion = [[NSInvocationOperation alloc] initWithTarget:self selector:@selector (log) object:nil ]; [operationQueue addOperation:invocationOpeartion]; [operationQueue addOperationWithBlock:^{ NSLog (@"block operation" ); [[NSOperationQueue mainQueue] addOperationWithBlock:^{ NSLog (@"execute in main thread" ); }]; }]; operationQueue.suspended = YES ; [operationQueue cancelAllOperations]; }
有一个问题要特别说明一下:
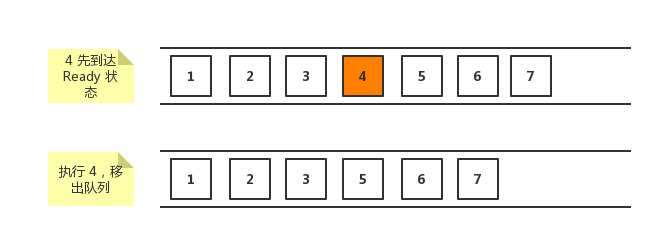
NSOperationQueue 和 GCD 中的队列不同。GCD 中的队列是遵循 FIFO 原则,先加入队列的先执行;NSOperationQueue 中的任务,根据谁先进入到 Ready 状态,谁先执行。如果有多个任务同时达到 Ready 状态,那么根据优先级来执行。
例如下面的任务中,4 先到达了 Ready 状态,4 先执行。并不是按照 1,2,3… 顺序执行。
基本原理 我们依然是在 swift 中找到相关源码,然后来进行分析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 public extension OperationQueue public static let defaultMaxConcurrentOperationCount: Int = Int .max } internal struct _OperationList var veryLow = [Operation ]() var low = [Operation ]() var normal = [Operation ]() var high = [Operation ]() var veryHigh = [Operation ]() var all = [Operation ]() mutating func insert (_ operation: Operation) mutating func remove (_ operation: Operation) mutating func dequeue () Operation ? { ... } var count : Int { return all.count } func map <T>(_ transform: (Operation) throws -> T ) rethrows -> [T ] { return try all.map (transform) } } open class OperationQueue : NSObject ... var __concurrencyGate: DispatchSemaphore ? var __underlyingQueue: DispatchQueue ? { didSet { let key = OperationQueue .OperationQueueKey oldValue?.setSpecific(key: key, value: nil ) __underlyingQueue?.setSpecific(key: key, value: Unmanaged .passUnretained(self )) } } ... internal var _underlyingQueue: DispatchQueue { lock.lock() if let queue = __underlyingQueue { lock.unlock() return queue } else { ... if maxConcurrentOperationCount == 1 { attr = [] __concurrencyGate = DispatchSemaphore (value: 1 ) } else { attr = .concurrent if maxConcurrentOperationCount != OperationQueue .defaultMaxConcurrentOperationCount { __concurrencyGate = DispatchSemaphore (value:maxConcurrentOperationCount) } } let queue = DispatchQueue (label: effectiveName, attributes: attr) if _suspended { queue.suspend() } __underlyingQueue = queue lock.unlock() return queue } } #endif ... internal func _dequeueOperation() Operation ? { lock.lock() let op = _operations.dequeue() lock.unlock() return op } open func addOperation (_ op: Operation) addOperations([op], waitUntilFinished: false ) } internal func _runOperation() if let op = _dequeueOperation() { if !op.isCancelled { op._waitUntilReady() if !op.isCancelled { op.start() } } } } open func addOperations (_ ops: [Operation], waitUntilFinished wait: Bool) #if DEPLOYMENT_ENABLE_LIBDISPATCH var waitGroup: DispatchGroup ? if wait { waitGroup = DispatchGroup () } #endif lock.lock() ops.forEach { (operation: Operation ) -> Void in operation._queue = self _operations.insert(operation) } lock.unlock() ops.forEach { (operation: Operation ) -> Void in #if DEPLOYMENT_ENABLE_LIBDISPATCH if let group = waitGroup { group.enter() } let block = DispatchWorkItem (flags: .enforceQoS) { () -> Void in if let sema = self ._concurrencyGate { sema.wait() self ._runOperation() sema.signal() } else { self ._runOperation() } if let group = waitGroup { group.leave() } } _underlyingQueue.async(group: queueGroup, execute: block) #endif } #if DEPLOYMENT_ENABLE_LIBDISPATCH if let group = waitGroup { group.wait() } #endif } internal func _operationFinished(_ operation: Operation) open func addOperation (_ block: @escaping () Swift .Void ) { ... } open var operations: [Operation ] { ... } open var operationCount: Int { ... } open var maxConcurrentOperationCount: Int = OperationQueue .defaultMaxConcurrentOperationCount internal var _suspended = false open var isSuspended: Bool { ... } ... open var qualityOfService: QualityOfService = .default open func cancelAllOperations () open func waitUntilAllOperationsAreFinished () #if DEPLOYMENT_ENABLE_LIBDISPATCH queueGroup.wait() #endif } static let OperationQueueKey = DispatchSpecificKey <Unmanaged <OperationQueue >>() open class var current : OperationQueue ? #if DEPLOYMENT_ENABLE_LIBDISPATCH guard let specific = DispatchQueue .getSpecific(key: OperationQueue .OperationQueueKey ) else { if _CFIsMainThread() { return OperationQueue .main } else { return nil } } return specific.takeUnretainedValue() #else return nil #endif } private static let _main = OperationQueue (_queue: .main, maxConcurrentOperations: 1 ) open class var main : OperationQueue }
代码很长,但是简单,可以直接通过注释来理解了。这里屡一下:
将每个 operation 加入到队列时,会根据优先级将 operation 分类存入 list 中,根据优先级执行。如果都不设置优先级,执行起来比较快一些。
加入到队列,会遍历每个 operation,取出进入 Ready 状态且没被 Cancel 的依次执行。
通过 concurrencyGate 这个信号量来控制并发数量。每当执行一个任务,wait 信号量减一,signal 信号量加一,当信号量为0时,一直等待,直接大于 0 才会正常执行。
每个方法中基本都加了锁,来保证线程安全。
自定义 NSOperation 之前说了自定义普通的 NSOperation,只需要重写 main 方法就可以了,但是因为我们没有处理并发情况,线程执行结束操作,KVO 机制,所以这种普通的不建议用来做并发任务。下面讲一下如何自定义并行的 NSOperation。
必须要实现的一些方法:
start 方法,在你想要执行的线程中调用此方法。不需要调用 super 方法 。main 方法,在 start 方法中调用,任务主体。isExecuting 方法,是否正在执行,要实现 KVO 机制。isConcurrent 方法,已经弃用,由 isAsynchronous 来代替。isAsynchronous 方法,在并发任务中,需要返回 YES。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 @interface BLOperation ()@property (nonatomic , assign ) BOOL executing;@property (nonatomic , assign ) BOOL finished;@end @implementation BLOperation @synthesize executing;@synthesize finished;- (instancetype )init { self = [super init]; if (self ) { executing = NO ; finished = NO ; } return self ; } - (void )start { if ([self isCancelled]) { [self willChangeValueForKey:@"isFinished" ]; finished = YES ; [self didChangeValueForKey:@"isFinished" ]; return ; } [self willChangeValueForKey:@"isExecuting" ]; [NSThread detachNewThreadSelector:@selector (main) toTarget:self withObject:nil ]; executing = YES ; [self didChangeValueForKey:@"isExecuting" ]; } - (void )main { NSLog (@"main begin" ); @try { @autoreleasepool { NSLog (@"custom operation" ); NSLog (@"currentThread = %@" , [NSThread currentThread]); NSLog (@"mainThread = %@" , [NSThread mainThread]); [self willChangeValueForKey:@"isFinished" ]; [self willChangeValueForKey:@"isExecuting" ]; executing = NO ; finished = YES ; [self didChangeValueForKey:@"isExecuting" ]; [self didChangeValueForKey:@"isFinished" ]; } } @catch (NSException *exception) { NSLog (@"exception is %@" , exception); } NSLog (@"main end" ); } - (BOOL )isExecuting { return executing; } - (BOOL )isFinished { return finished; } - (BOOL )isAsynchronous { return YES ; } @end
关于 NSBlockOpeartion,主要实现了 main 方法,然后用一个数组保存加进来的其他 block,源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 open class BlockOperation: Operation { typealias ExecutionBlock = () -> Void internal var _block: () -> Void internal var _executionBlocks = [ExecutionBlock]() public init(block: @escaping () -> Void) { _block = block } override open func main() { lock.lock() let block = _block let executionBlocks = _executionBlocks lock.unlock() block() executionBlocks.forEach { $0 () } } open func addExecutionBlock(_ block: @escaping () -> Void) { lock.lock() _executionBlocks.append(block) lock.unlock() } open var executionBlocks: [() -> Void] { lock.lock() let blocks = _executionBlocks lock.unlock() return blocks } }
关于 NSOperation 的相关东西,到此结束。
在开发中的一些问题 相对于 API 的使用和基本原理的了解,我认为最重要的还是这一部分。毕竟我们还是要拿这些东西来开发的。并发编程中有很多坑,这里简单介绍一些。
1. NSNotification 与多线程问题 我们都知道,NSNotification 在哪个线程 post,最终就会在哪个线程执行。如果我们不是在主线程 post 的,但是却在主线程接收的,而且我们期望 selector 在主线程执行。这时候我们需要注意下,在 selector 需要 dispatch 到主线程才可以。当然你也可以使用 addObserverForName:object:queue:usingBlock: 来指定执行 block 的 queue。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @implementation BLPostNotification - (void )postNotification { dispatch_queue_t queue = dispatch_queue_create("com.bool.post.notification" , DISPATCH_QUEUE_SERIAL); dispatch_async (queue, ^{ [[NSNotificationCenter defaultCenter] postNotificationName:@"downloadImage" object:nil ]; }); } @end @implementation ImageViewController - (void )viewDidLoad { [super viewDidLoad]; [[NSNotificationCenter defaultCenter] addObserver:self selector:@selector (show) name:@"downloadImage" object:nil ]; } - (void )showImage { dispatch_async (dispatch_get_main_queue(), ^{ }); } @end
2. NSTimer 与多线程问题 使用 NSTimer 时,在哪个线程生成的 timer,就在哪个线程销毁,否则会有意想不到的结果。官方这样描述的:
However, for a repeating timer, you must invalidate the timer object yourself by calling its invalidate method. Calling this method requests the removal of the timer from the current run loop; as a result, you should always call the invalidate method from the same thread on which the timer was installed .
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 @interface BLTimerTest ()@property (nonatomic , strong ) dispatch_queue_t queue;@property (nonatomic , strong ) NSTimer *timer;@end @implementation BLTimerTest - (instancetype )init { self = [super init]; if (self ) { _queue = dispatch_queue_create("com.bool.timer.test" , DISPATCH_QUEUE_SERIAL); } return self ; } - (void )installTimer { dispatch_async (self .queue, ^{ self .timer = [NSTimer scheduledTimerWithTimeInterval:3.0 f repeats:YES block:^(NSTimer * _Nonnull timer) { NSLog (@"test timer" ); }]; }); } - (void )clearTimer { dispatch_async (self .queue, ^{ if ([self .timer isValid]) { [self .timer invalidate]; self .timer = nil ; } }); } @end
3. Dispatch Once 死锁问题 在开发中,我们经常使用 dispatch_once,但是递归调用会造成死锁。例如下面这样:
1 2 3 4 5 6 - (void )dispatchOnceTest { static dispatch_once_t onceToken; dispatch_once (&onceToken, ^{ [self dispatchOnceTest]; }); }
至于为什么会死锁,上文介绍 Dispatch Once 的时候已经说明了,这里就不多做介绍了。提醒一下使用的时候要注意,不要造成递归调用。
4. Dispatch Group 问题 在使用 dispatch_group 的时候,dispatch_group_enter(taskGroup) 和 dispatch_group_leave(taskGroup) 一定要成对,否则也会出现崩溃。大多数情况下我们都会注意,但是有时候可能会疏忽。例如多层 for loop 时 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 - (void )testDispatchGroup { NSString *path = @"" ; NSFileManager *fileManager = [NSFileManager defaultManager]; NSArray *folderList = [fileManager contentsOfDirectoryAtPath:path error:nil ]; dispatch_group_t taskGroup = dispatch_group_create(); for (NSString *folderName in folderList) { dispatch_group_enter(taskGroup); NSString *folderPath = [@"path" stringByAppendingPathComponent:folderName]; NSArray *fileList = [fileManager contentsOfDirectoryAtPath:folderPath error:nil ]; for (NSString *fileName in fileList) { dispatch_async (_queue, ^{ dispatch_group_leave(taskGroup); }); } } }
上面的 dispatch_group_enter(taskGroup) 在第一层 for loop 中,而 dispatch_group_leave(taskGroup) 在第二层 for loop 中,两者的关系是一对多,很容造成崩溃。有时候嵌套层级太多,很容易忽略这个问题。
总结 关于 iOS 并发编程,就总结到这里。后面如果有一些 best practices 我会更新进来。另外,因为文章比较长,可能会出现一个错误,欢迎指正,我会对此加以修改。
参考文献
深入理解 iOS 开发中的锁 关于 @synchronized,这儿比你想知道的还要多 深入理解 GCD GCD源码分析2 —— dispatch_once篇 GCD源码分析6 —— dispatch_source篇 Dispatch Task Management - Operation swift-corelibs-foundation Advanced NSOperations